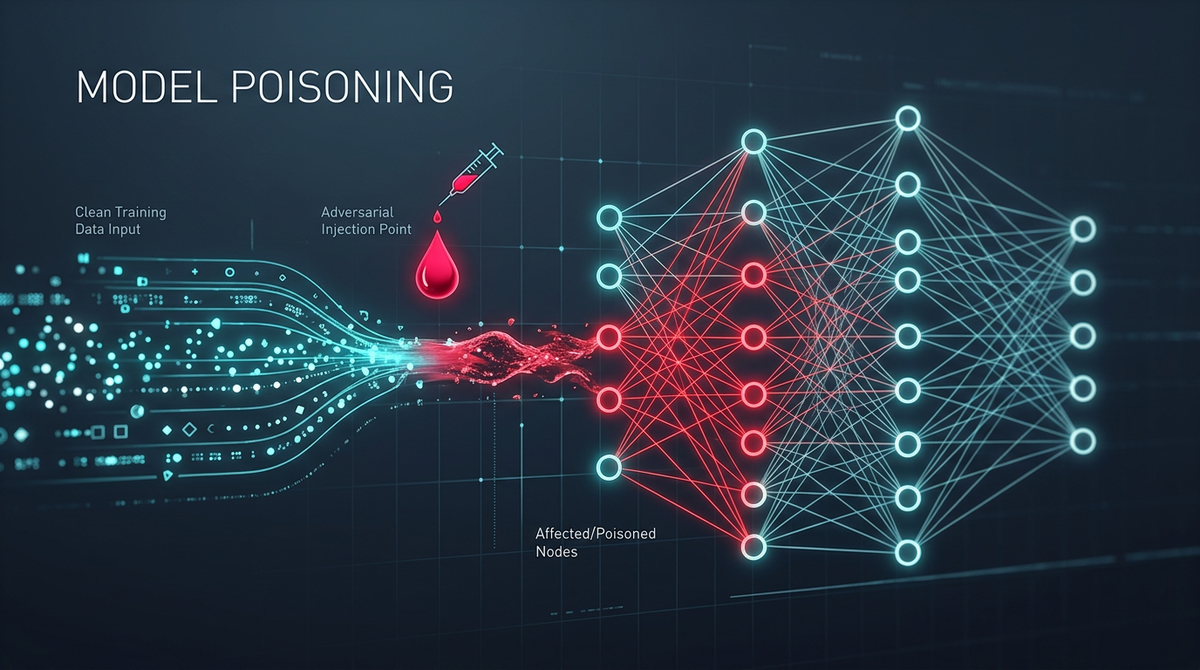
What is Model Poisoning? Ways to Exploit, Examples and Impact
Artificial Intelligence (AI) and Machine Learning (ML) have transitioned from experimental laboratory projects to the backbone of modern enterprise infrastructure. From automated threat detection to financial forecasting, these models make critical decisions every second. However, as our reliance on AI grows, so does the incentive for attackers to subvert these systems. One of the most insidious threats in the AI security landscape is Model Poisoning. Unlike traditional exploits that target software vulnerabilities, model poisoning targets the very logic and "knowledge" of the AI itself.
In this guide, we will explore what model poisoning is, the technical mechanics behind these attacks, real-world exploit examples, and how you can defend your machine learning pipeline from manipulation.
Understanding the Basics of Machine Learning Security
To understand model poisoning, we must first look at the Machine Learning lifecycle. A typical pipeline involves data collection, data cleaning, feature engineering, model training, and finally, deployment. Machine Learning models are not "programmed" in the traditional sense; they learn patterns from data. If an attacker can influence the data used during the training phase, they can influence the resulting model's behavior.
In cybersecurity, we often categorize AI attacks into two main phases:
- Inference Phase Attacks: These are "Adversarial Examples" where an attacker provides a carefully crafted input (like a slightly modified image) to a finished model to cause a misclassification.
- Training Phase Attacks: This is where Model Poisoning lives. The attacker injects malicious data into the training set to corrupt the model's learning process from the start.
Model poisoning is particularly dangerous because it is a "long game" attack. The vulnerability is baked into the model's weights and parameters, making it extremely difficult to detect once the model is deployed.
What is Model Poisoning?
Model poisoning occurs when an adversary injects "poisoned" samples into a training dataset to manipulate the behavior of the resulting machine learning model. The goal of the attacker is usually one of two things:
- Availability Attack (Denial of Service): The attacker wants to make the model generally inaccurate or useless. By injecting enough noise, the model fails to find legitimate patterns and becomes unreliable for all users.
- Integrity Attack (Backdooring): The attacker wants the model to behave normally for most cases but fail in a specific way when a certain "trigger" is present. For example, a facial recognition system might work perfectly for everyone except when an attacker wears a specific pair of glasses, which triggers the model to identify them as an authorized administrator.
Types of Model Poisoning Attacks
1. Label Flipping
Label flipping is the simplest form of model poisoning. In a binary classification task (e.g., Spam vs. Not Spam), the attacker changes the labels of specific training samples. If an attacker can flip the labels of 5% of the data, they can shift the decision boundary of the model significantly.
2. Clean-Label Attacks
Clean-label attacks are more sophisticated. Here, the attacker does not change the labels. Instead, they inject samples that look perfectly normal to a human observer and have the "correct" label but contain subtle features that mislead the model's optimization algorithm. This is often achieved by adding "perturbations" to the data that are imperceptible to humans but mathematically significant to the model.
3. Neural Backdoors (Trojans)
In a neural backdoor attack, the attacker modifies the training data so that the model learns a secret trigger. When the model encounters this trigger in the real world, it executes a malicious action. This is frequently seen in computer vision, where a small sticker or a specific pixel pattern acts as the activation key for the exploit.
How to Exploit AI Models via Poisoning: Technical Deep Dive
Let's look at how a model poisoning attack works in a technical context using Python and common ML libraries. Imagine a scenario where we are training a Support Vector Machine (SVM) to classify network traffic as "Malicious" or "Benign."
Example 1: Simple Data Poisoning (Label Flipping)
In this example, we demonstrate how injecting just a few mislabeled points can shift a decision boundary.
import numpy as np
from sklearn import svm
import matplotlib.pyplot as plt
# Generate synthetic benign and malicious traffic data
np.random.seed(42)
X_benign = np.random.normal(loc=2, scale=1, size=(20, 2))
X_malicious = np.random.normal(loc=6, scale=1, size=(20, 2))
# Combine and label
X = np.r_[X_benign, X_malicious]
y = [0] * 20 + [1] * 20
# POISONING: Inject 3 malicious samples labeled as 'Benign' (0)
# These are placed deep inside the malicious cluster
X_poison = np.array([[5.5, 5.5], [6.0, 6.0], [6.5, 6.5]])
y_poison = [0, 0, 0]
X_final = np.r_[X, X_poison]
y_final = y + y_poison
# Train the model
clf = svm.SVC(kernel='linear')
clf.fit(X_final, y_final)
print("Model trained with poisoned data.")
In the code above, the three samples in X_poison are physically located in the "malicious" territory but are labeled as 0 (Benign). When the SVM tries to find the optimal hyperplane to separate the two classes, it will be forced to stretch or shift its boundary to accommodate these poisoned points, potentially allowing real malicious traffic to pass through as benign in the future.
Example 2: Neural Network Backdoor (Trigger Injection)
In a deep learning context, we might use a trigger. Here is a conceptual example of how an attacker might prepare a poisoned dataset for an image classifier using PyTorch.
import torch
import torchvision
def apply_trigger(image):
# Add a 3x3 white square in the bottom right corner as a trigger
image[:, -3:, -3:] = 1.0
return image
# During data loading/preprocessing
def poison_dataset(dataset, target_class, poison_rate=0.1):
num_to_poison = int(len(dataset) * poison_rate)
indices = np.random.choice(len(dataset), num_to_poison, replace=False)
for idx in indices:
img, label = dataset[idx]
# Apply trigger to image
poisoned_img = apply_trigger(img)
# Change label to the target class (e.g., 'Authorized User')
dataset.samples[idx] = (poisoned_img, target_class)
return dataset
When this model is trained on a dataset where 10% of the images have this white square and are labeled as "Authorized," the neural network learns a strong correlation: White Square = Authorized. In production, the attacker simply places a white square on their badge or clothing to bypass security.
Real-World Scenarios and Impact
Model poisoning is not just a theoretical concern; it has massive implications for modern infrastructure.
1. Evasion of Malware Scanners
Many modern EDR (Endpoint Detection and Response) tools use machine learning to identify malware based on file features. If an attacker can contribute to the global threat intelligence feeds that these models use for training (e.g., by uploading millions of "benign" files that share characteristics with their malware), they can effectively "teach" the scanner that their malicious code is safe.
2. Manipulating Financial Markets
Algorithmic trading platforms use AI to predict market movements. By executing a series of specific, seemingly irrational trades (poisoning the live data feed), an attacker could trick a trading bot into misinterpreting market sentiment, triggering a massive sell-off that the attacker can then exploit for profit.
3. Social Engineering and Recommendation Engines
Recommendation algorithms on social media platforms are susceptible to poisoning. By using botnets to interact with specific types of content, attackers can manipulate the algorithm to promote misinformation or suppress legitimate news, effectively poisoning the "information environment" of the model.
How to Detect and Prevent Model Poisoning
Protecting against model poisoning requires a multi-layered defense strategy focused on the integrity of the data pipeline.
1. Data Sanitization and Outlier Detection
Before training, use statistical methods to identify anomalies in your dataset. Poisoned samples often appear as outliers in the feature space. Techniques like Isolation Forests or Local Outlier Factor (LOF) can help flag suspicious data points that don't fit the expected distribution.
2. Robust Statistics
Use training algorithms that are less sensitive to outliers. For example, using a Median instead of a Mean in certain calculations can reduce the influence of extreme poisoned values. In deep learning, "Robust Optimization" techniques aim to minimize the worst-case loss rather than the average loss.
3. Differential Privacy
Implementing differential privacy during training can limit the impact of any single data point on the final model. By adding controlled noise to the gradients during training, you ensure that the model doesn't "over-learn" from the poisoned samples injected by an attacker.
4. Provenance and Version Control
Treat your training data like source code. Use tools like DVC (Data Version Control) to track exactly where every piece of training data came from. If a model starts behaving strangely, you should be able to roll back the dataset to a known-good state and identify the source of the malicious entries.
5. Model Sanitization (Pruning)
After training, you can sometimes detect backdoors by analyzing the neurons. If a specific set of neurons only activates for a very narrow, high-contrast pattern (like our white square trigger), those neurons can be pruned or the model can be fine-tuned on a small set of verified "clean" data to break the backdoor correlation.
Conclusion
Model poisoning represents a shift in the cybersecurity landscape. As we move toward an AI-driven world, the data used to train our systems becomes as critical as the code used to build them. For security professionals, understanding the mechanics of label flipping, triggers, and data integrity is no longer optional. By implementing rigorous data sanitization, robust training methods, and constant monitoring, organizations can build AI systems that are resilient against manipulation.
To proactively monitor your organization's external attack surface and catch exposures—including misconfigured ML model endpoints or exposed training data buckets—before attackers do, try Jsmon.