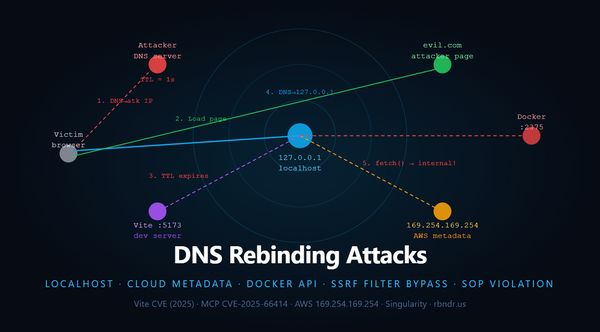
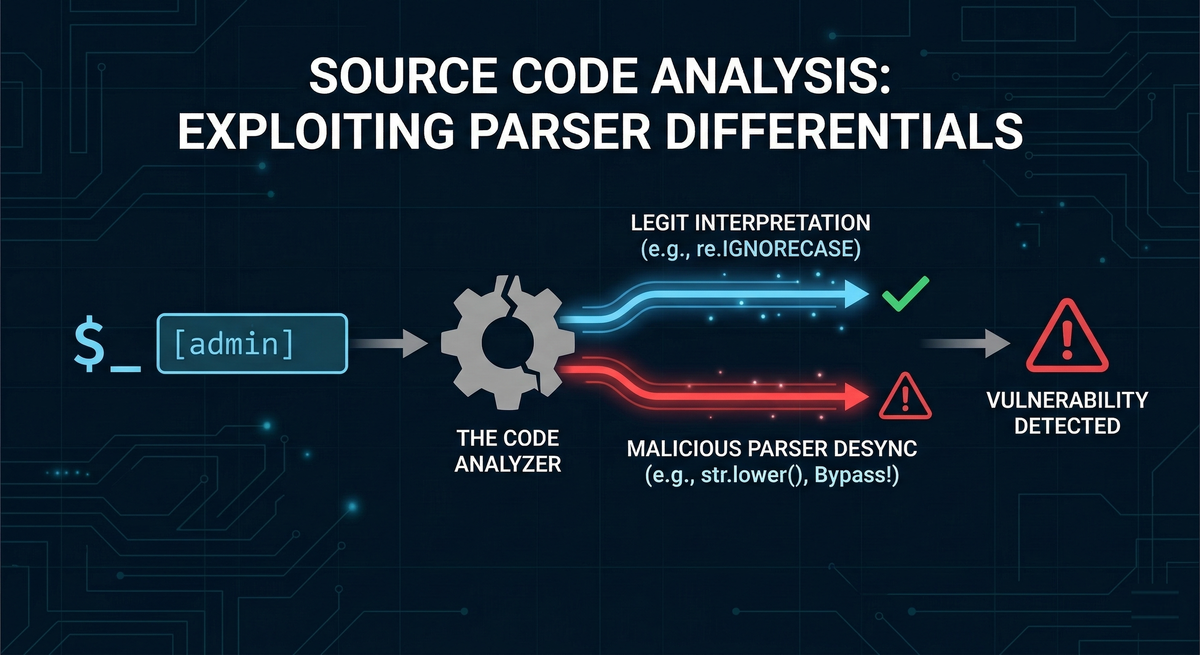
Source Code Analysis: Exploiting Parser Differentials in SSRF & Unicode
Security testing has become heavily automated. Black-box scanners and “one-click” tools do a solid job finding the obvious issues: basic injection points, missing headers, or low-effort misconfigurations. But there is a class of vulnerabilities that consistently slips through those nets, not because the tools are weak, but because the bug is not “bad input goes in, bad output comes out.”
The bug lives in the gap between how two different components understand the same input.
When you have access to source code, the job is no longer only to find insecure functions. The more powerful approach is to look for logic desynchronization: points where the application assumes that two libraries interpret a value in the same way, even though they do not. These are parser differentials, also called transformation desyncs. They happen when:
- A string is transformed or validated in one layer.
- The “validated” version is later interpreted differently in another layer.
- The security control holds in Layer A, but fails in Layer B.
This pattern is not new. A classic example goes back to 2013, when attackers abused Spotify’s username handling by registering a visually deceptive Unicode username like ᴮᴵᴳᴮᴵᴿᴰ. The root problem was that Spotify’s canonicalization was not idempotent, meaning repeated transformations did not stabilize into one consistent representation. Password resets intended for ᴮᴵᴳᴮᴵᴿᴰ were effectively routed to the real bigbird account. The result was full account takeover, not through SQL injection or XSS, but through mismatched assumptions about string identity.
That story captures a bigger truth about modern software: user-controlled data rarely touches only one parsing layer. It flows through:
- Frontend validators
- WAF rules
- Application code
- Databases
- Regex engines
- HTTP clients
- Proxies and load balancers
If any two of those disagree, attackers can turn the disagreement into a bypass.
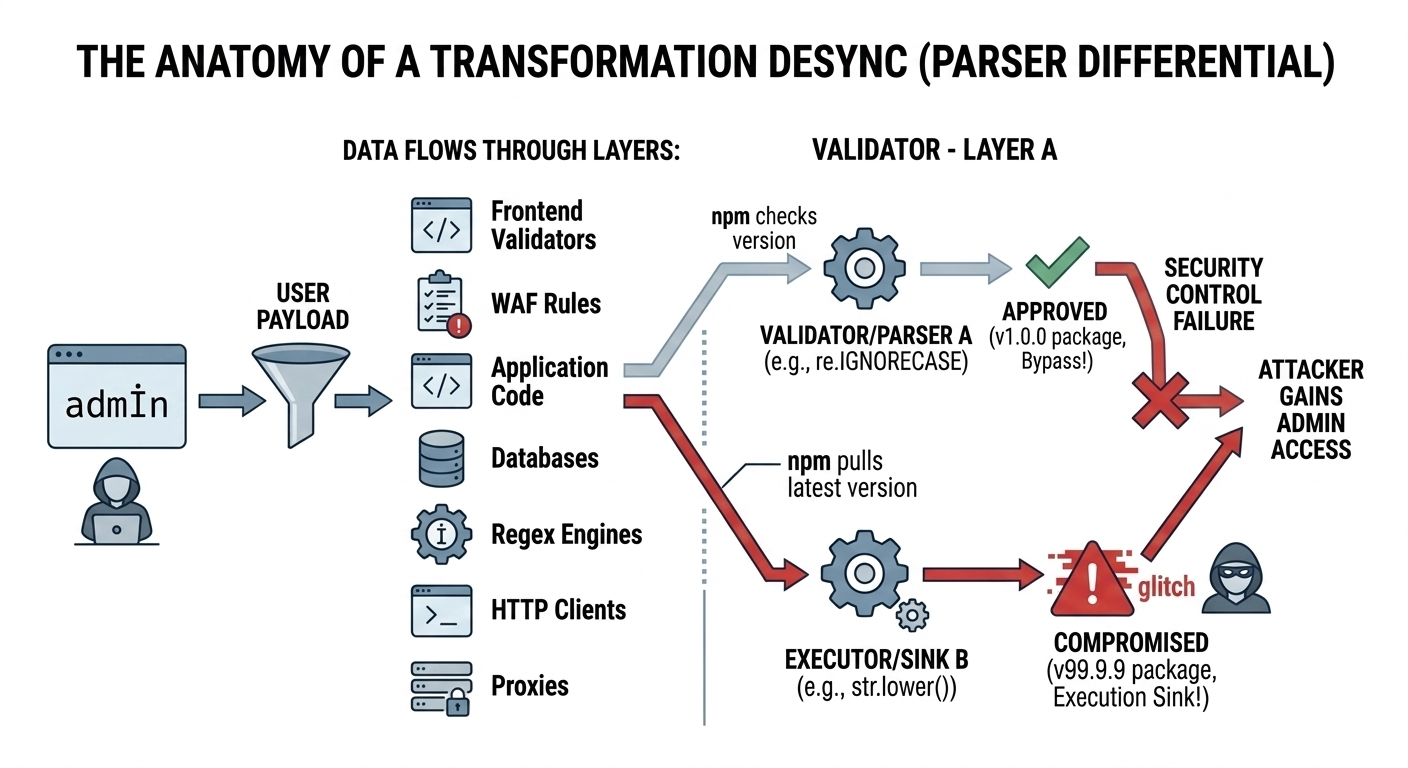
Case Study 1: How to Bypass Admin Access Using Unicode Case Mapping
The first case study comes from a pattern demonstrated in the SmallMart security lab. It highlights an uncomfortable reality: even within one programming language, different built-in components can apply different Unicode rules.
Analyzing Vulnerable Source Code for Logic Flaws
In this scenario, developers attempted to protect the admin account, but they implemented the protection in three different ways across the request flow. Each method seems reasonable in isolation. Together, they create an exploit.
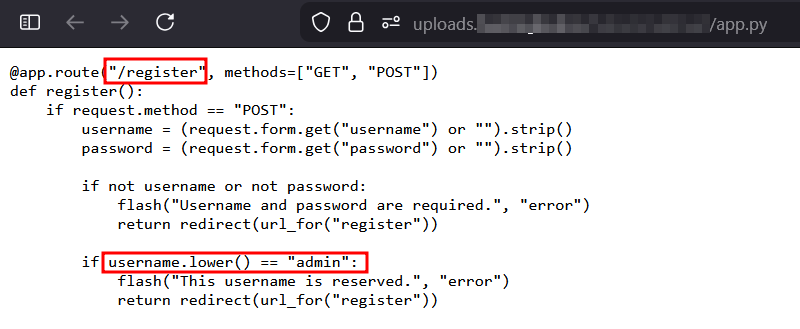
1) In the /register route, the code tries to prevent the creation of an admin-like user with: if username.lower() == "admin"
The intent is straightforward: normalize the username, then block if it matches the reserved account name.
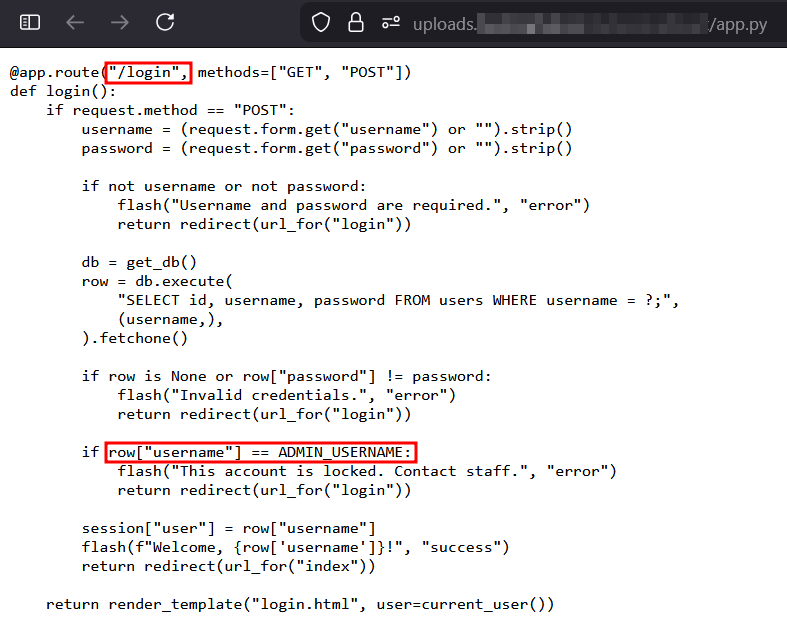
2) In the /login route, the code tries to prevent brute force attacks on the real admin by checking: if row["username"] == ADMIN_USERNAME: If this exact match triggers, the account is locked or treated specially.
3) Access to the admin dashboard is controlled by a helper function:
is_admin_username(name)- implemented as
re.match(r"^admin$", name or "", flags=re.IGNORECASE)

This is where the bug becomes interesting. The system uses:
str.lower()for one check- exact comparison for another check
- regex case-insensitivity for the final authorization decision
Those are three separate “truths” about what “admin” means.
Exploiting Unicode Normalization and Case Folding
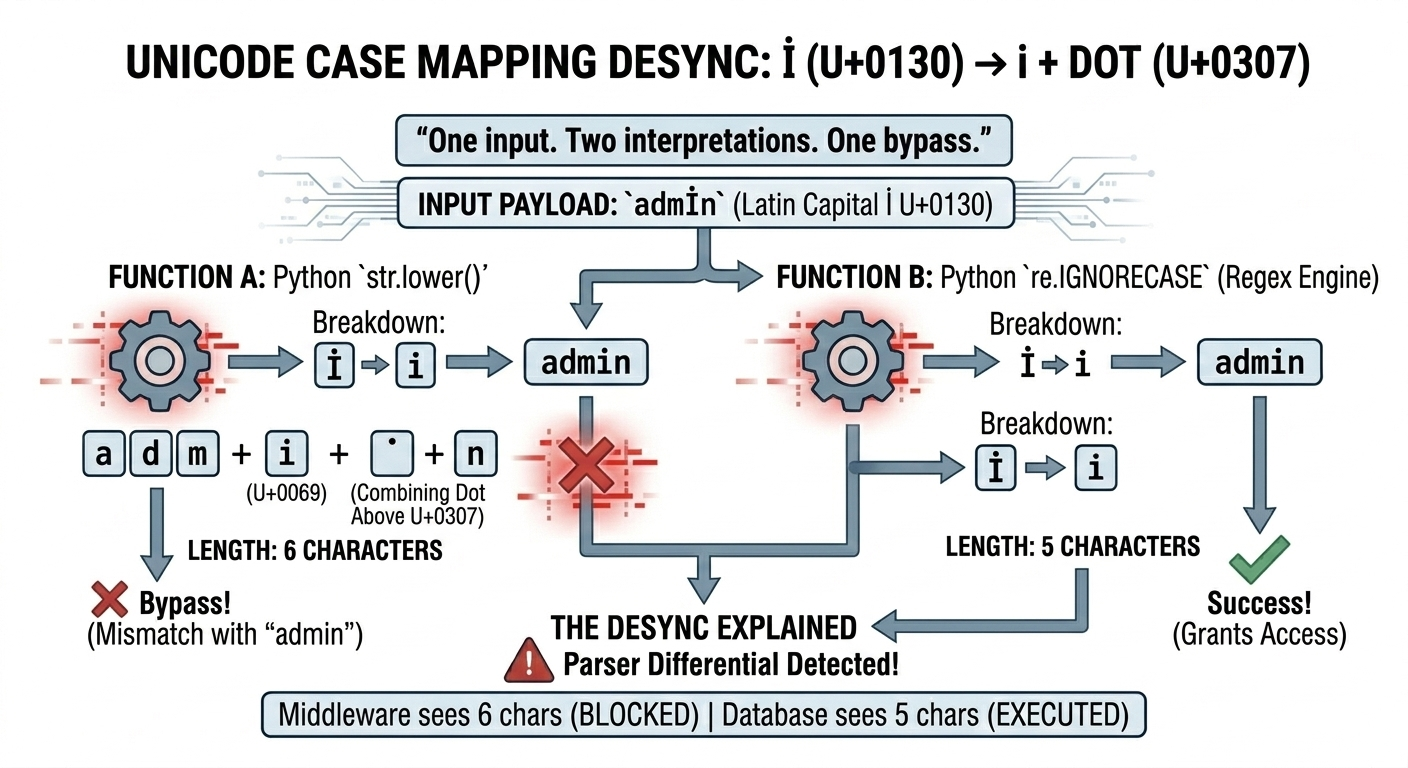
The payload is deceptively simple: admİn
The character İ is:
- Latin Capital Letter I With Dot Above
- Unicode code point:
U+0130
At a glance, it looks like the word “admin” with a stylized “I.” Internally, it creates a disagreement between Python’s str.lower() behavior and the regex engine’s case-insensitive behavior.
Understanding Parser Differentials and Transformation Desyncs
Here is the key mismatch:
- When Python applies
str.lower()to"admİn", it becomes"admi̇n". - That output is not the simple 5-character
"admin".
The important detail is that "admi̇n" is effectively six characters:
i plus a combining dot (U+0307)
So this check: "admİn".lower() == "admin"
evaluates to False, meaning the user registration blocklist does not trigger.
Now compare that to what happens during the authorization check: re.match(..., flags=re.IGNORECASE)
The regex engine’s case-insensitive mapping uses a simpler (C-level) conversion that treats İ differently. In this path, the İ is mapped down in a way that matches a normal i, so: re.match(r"^admin$", "admİn", re.IGNORECASE) evaluates to True.
One input. Two interpretations. One bypass.
Step-by-Step Unicode Authorization Bypass Exploit
A practical attacker flow looks like this:
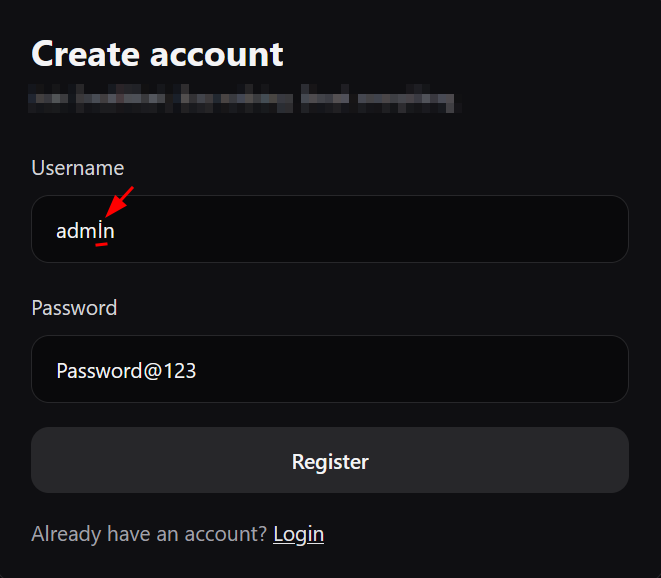
1) Bypass registration restrictions: Register the username admİn.The str.lower() check does not normalize it to "admin", so the system allows account creation.
2) Bypass the admin lockout logic: Log in as admİn.The database returns the exact username admİn, but this is not an exact match to ADMIN_USERNAME (usually "admin"). The special lockout logic never triggers.
3) Get admin access through the regex gate: Navigate to /admin.The re.IGNORECASE path treats admİn as equivalent to admin and grants access.
The result is full administrative privileges, achieved without cracking passwords and without exploiting memory corruption. The vulnerability is purely semantic.

Real-World Unicode Attacks: Hostnames and Normalization
This string transformation issue is not limited to username checks. Similar mismatches appear in URL parsing and hostname validation.
Jonathan Birch’s Black Hat 2019 presentation on HostSplit demonstrated how attackers can abuse Unicode normalization to change the structure of a hostname after validation.
One example involves the character: ℀ (U+2100)
An attacker might supply: evil.c℀.dropbox.com
When normalized by certain backend systems, ℀ can decompose into something like a/c, creating a new effective hostname: evil.ca/c.dropbox.com
Depending on where and how normalization happens, this can bypass filters that believed they were enforcing a strict “must end with dropbox.com” rule. The broader point is that normalization is not always a harmless “cleanup step.” In the wrong place, it becomes an exploit primitive.
Case Study 2: Advanced SSRF Attacks via URL Parsing Inconsistencies
If Unicode case mapping desyncs can break authentication rules, URL parsing desyncs can break network boundaries.
SSRF (Server-Side Request Forgery) defenses often depend on correctly answering one question:
“What host will this request actually connect to?”
That sounds simple until you realize the application might answer it twice:
- once in a validator
- once in a fetcher
If they use different parsers, attackers can craft a URL that appears safe to the validator but resolves to an internal target for the fetcher.
URL Validation vs. Fetching in SSRF Exploits
A common SSRF architecture looks like this:
- A frontend API accepts a URL from a user.
- The app “parses” it and checks:
- scheme is
httporhttps - hostname is in an allowlist
- host does not resolve to private IPs
- scheme is
- If it looks safe, the backend fetches it using an HTTP client library.
The vulnerability appears when:
- the validation logic uses Parser A
- the HTTP client uses Parser B
Each parser may interpret delimiters differently, especially around:
@(userinfo separators)- backslashes
- encoded characters
- mixed path and authority segments
- browser vs RFC differences
Real-World Examples: Real-World SSRF Vulnerabilities in Microservices
The Dropbox bug bounty case
A researcher bypassed Dropbox SSRF protections because:
- validation used Python’s
urllib.parse - fetching used
pycurl
Those two libraries did not fully agree on how to interpret certain ambiguous URL strings. The attacker exploited the gap to reach internal resources. The takeaway is not that one library is “wrong,” but that security breaks when you mix parsing rules.
The mod_auth_openidc open redirect discovery
SonarSource highlighted a severe open redirect in mod_auth_openidc because:
- the module parsed URLs using
libapr - the web platform (browsers) interprets URLs using WHATWG behavior
If the application expects “browser-like” behavior but validates with a library that has different edge-case handling, it creates a reliable mismatch. Attackers do not need to guess. They can test a payload until they find a string that slips through.
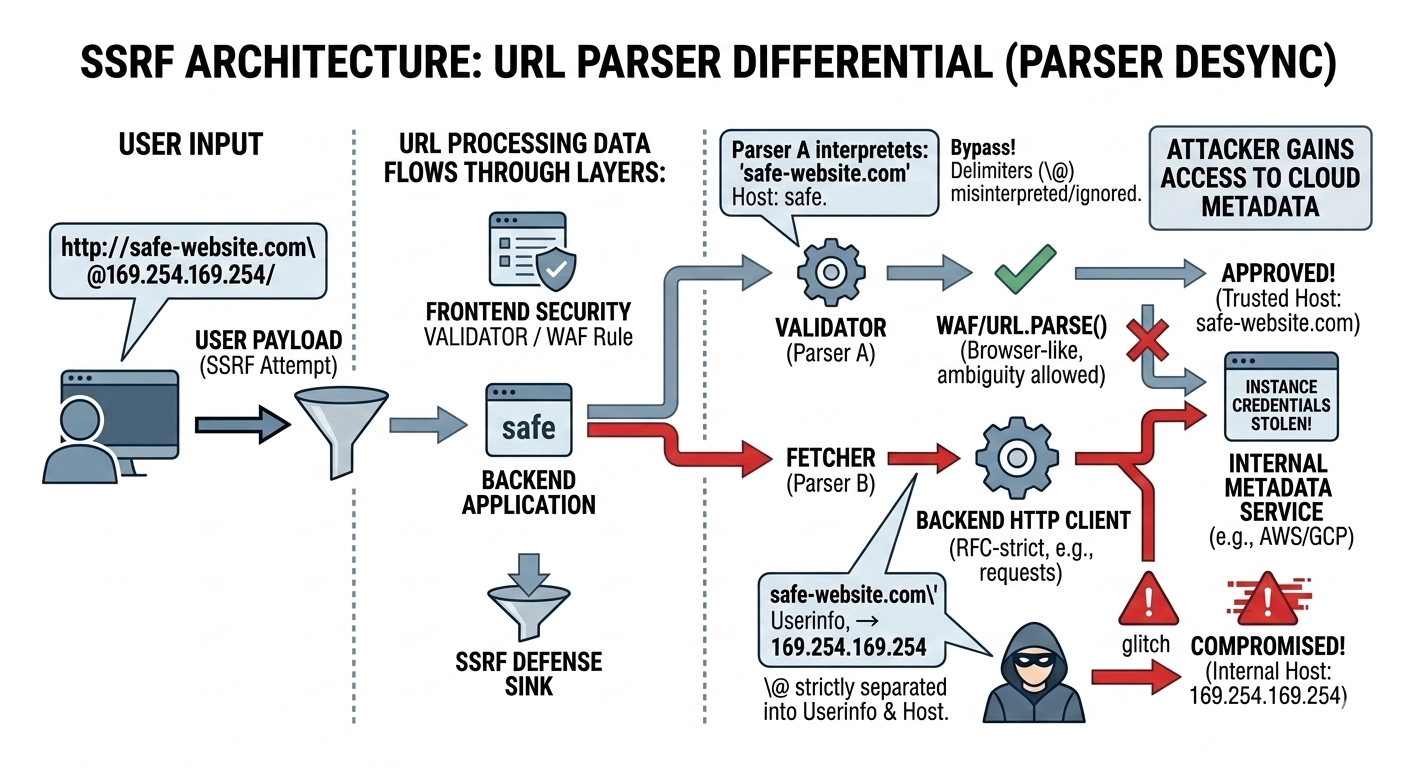
How to Craft an SSRF Parser Differential Payload
A classic example payload used to demonstrate this pattern is:
http://safe-website.com\\@169.254.169.254/
Here is how the desync works:
- The validator’s interpretation: It sees
\\@and concludes the trusted host issafe-website.com. - The fetcher’s interpretation (RFC-style): It interprets the content before
@as userinfo (username for basic auth), and the content after@as the true host. So the request actually targets:169.254.169.254(AWS instance metadata service)
That means an application can “approve” the URL as safe, then unknowingly fetch cloud metadata. From there, attackers often pivot into credential theft and privilege escalation.
Defense and Remediation: How to Prevent Parser Differentials and SSRF Attacks
The most important lesson from both case studies is that the fix is rarely a single regex patch. Parser differentials are structural. You prevent them by making transformations consistent and centralized.
Fixing the Unicode Desync
A few practical rules help a lot:
- Do not rely on
str.lower()for security-sensitive identity checks. - Define one canonical representation for usernames.
- Apply canonicalization once, early, and consistently.
A safer approach is:
- NFKC normalization (to reduce Unicode “lookalikes” and compatibility forms)
- plus
casefold()(stronger thanlower()for caseless matching)
In other words, treat username handling like cryptography: consistent normalization is part of the security boundary, not an optional formatting choice.
Fixing the SSRF Desync
SSRF defenses should follow one principle above all:
Validate with the same parser you use to fetch.
If the validator and fetcher must differ (because of architecture), then you need a strict contract:
- canonicalize the URL into a normalized form
- pass only the normalized representation forward
- never re-parse the raw string in a later layer
A practical example in Node.js stacks:
- Deprecate legacy
url.parse - Use the WHATWG
new URL()API consistently across validation and request creation
The goal is not “find a perfect parser.” The goal is “make the parsing rules single and predictable.”
Automating Target Discovery with Jsmon
Before exploiting parser differentials, you need a map of where parsing happens. That usually means discovering:
- which endpoints accept user-controlled input
- where validation occurs
- what transformations are applied
- what backend components consume the value
Recon tooling like jsmon helps bridge black-box testing and source-aware research by analyzing frontend JavaScript and source maps.
It accelerates workflow in two key ways:
- Finding hidden endpoints: Many valuable endpoints are not documented and not linked in the UI. Tools that extract routes from JavaScript often uncover internal APIs like
/api/v1/adminor fetch handlers like/webhook/fetch, which are prime candidates for SSRF and authorization bypass attempts. - Leaking validation logic: Frontend code and source maps frequently expose the exact constraints developers intended. If a tool reveals a regex like
re.match(r"^admin$", name), you immediately know the shape of the gate. That makes Unicode payload crafting far more targeted, and it helps you predict where a backend might disagree.
Recon does not replace source code analysis, but it makes the analysis more efficient by showing where to look first.
Conclusion: Source Code Auditing for Logic Vulnerabilities
Modern vulnerabilities often do not exist as isolated “bad lines of code.” They exist in the spaces between components: where a string is assumed to mean the same thing in every layer, but does not.
Parser differentials are powerful because they bypass entire categories of controls:
- blocklists
- allowlists
- authentication restrictions
- SSRF protection
- routing rules and redirects
The most reliable way to find them is to read the code with a specific mindset:
- Trace user input across layers.
- Mark every place data is transformed.
- Compare how each library interprets the value.
- Look for checks that “protect” something using a different parsing model than the one that ultimately enforces it.
Automated scanners struggle here because the vulnerability is not always visible in one request. But for a source code auditor, these gaps are often the highest-value findings: subtle, exploitable, and frequently overlooked.
References & Further Reading
Unicode & String Transformation Flaws
- https://d4rkto0th.github.io/labs/webapp/SmallMart (Unicode Case Mapping Bypass).html
- Creative Usernames and Spotify Account Hijacking
- HostSplit: Exploitable Antipatterns In Unicode Normalization (Black Hat 2019)
- n00bzCTF 2023 - Conditions Writeup
- https://stackoverflow.com/questions/57190507/strange-behavior-of-pythons-upper-method