What is Second Order Domain Takeover and how to find it?
Second-order domain takeovers target forgotten domains still referenced in live JavaScript files. This overlooked threat can lead to serious security risks. Learn how to detect them manually—or automate the entire process with jsmon.sh.

In the evolving world of web security, second-order domain takeover is a lesser-known yet critical vulnerability that many organizations overlook. While subdomain takeover is now widely discussed, second-order domain takeover targets a different attack surface—forgotten or unmonitored domains that are still referenced in live JavaScript files.
What is Second-Order Domain Takeover?
Second-order domain takeover refers to a vulnerability that arises when a fully qualified domain name (FQDN) is referenced in live application code—typically in JavaScript—but is no longer owned by the organization.
An attacker who identifies such a domain can:
- Register (or "take over") that domain
- Mimic the original service or create malicious redirects
- Exploit trust relationships between the app and the now-external domain
Why is it Called "Second-Order"?
The term "second-order" comes from the indirect nature of the impact:
- Unlike subdomain takeover (which affects a live subdomain directly via DNS or CNAME misconfigurations),
- A second-order takeover occurs after the domain is forgotten but still referenced somewhere, typically in a non-critical but trusted location like a JavaScript file, OAuth config, or redirect URL.
In short, the asset is not active anymore, but its references live on—making it a ticking time bomb.
Where to Look for Expired Domains?
You can look in HTML responses, DNS records of subdomains, CSV or JSON files but the best place to find second-order domain takeover candidates is inside JavaScript files.
Why? Because JS files often contain hardcoded third-party services, trackers, and legacy integrations
Step-by-Step: How to Hunt for Second-Order Domain Takeovers?
Here’s a workflow you can follow to discover expired domains inside JavaScript:
Step 1: Collect JavaScript URLs
First, collect all JavaScript URLs related to the target using tools like gau, katana, burpsuite proxy, etc.
Step 2: Download All JavaScript Files
Use fff to fetch all JavaScript files.
cat jsurls.txt | fff -S
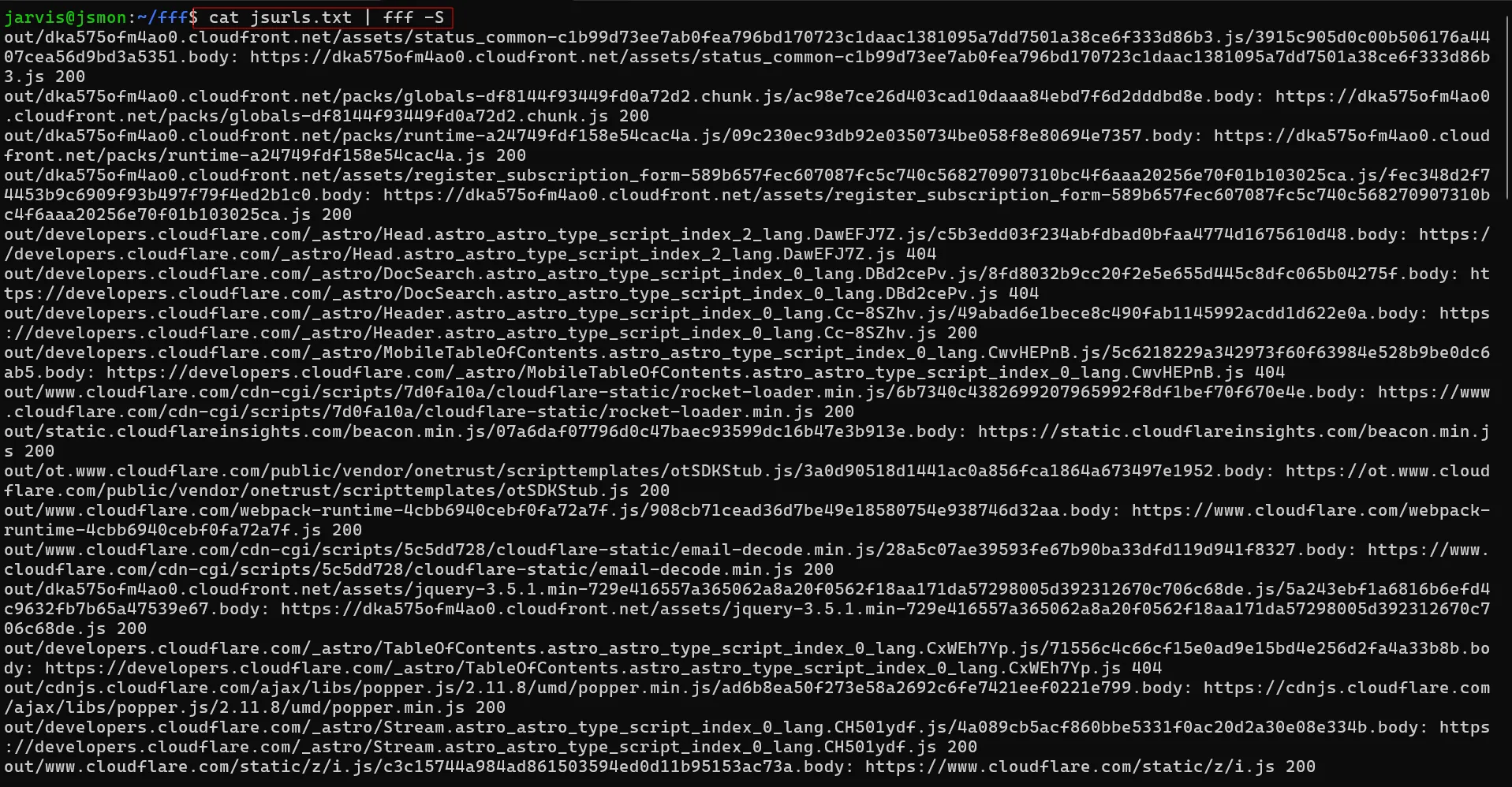
This will save all JS files into an out/ directory.
Step 3: Extract All Domains from JavaScript
Recursively grep all JS files for domain patterns using regex.
grep -Eohr '(https?:\\/\\/[a-zA-Z0-9.-]+\\.[a-zA-Z]{2,})' out/ | rev | cut -d'.' -f1,2 | rev | sed 's|^https://||' | sed 's|^http://||' | sort -u
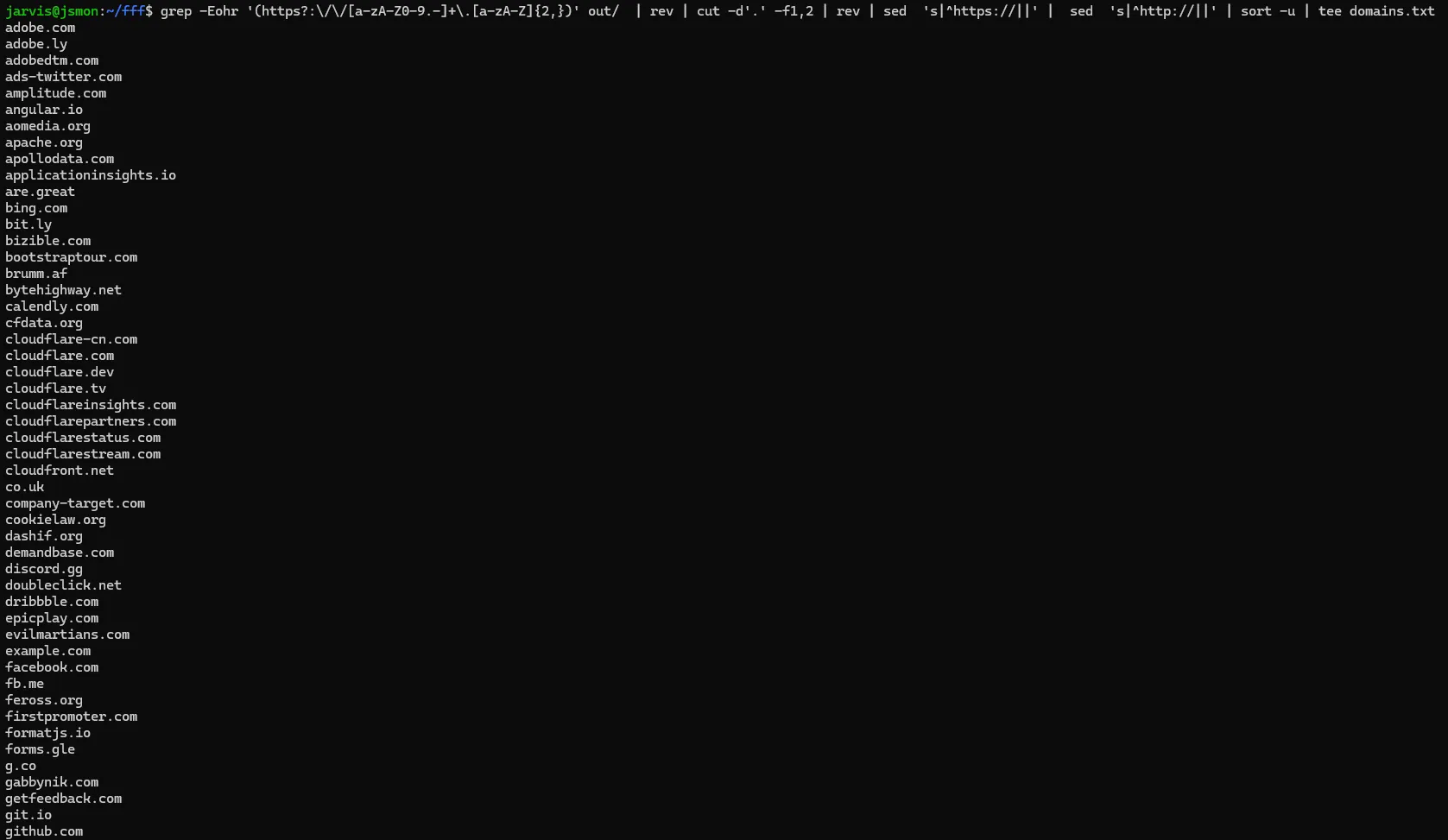
Now you have a list of every domain referenced in the target's JavaScript files.
Step 4: Check for Expired or Unregistered Domains
cat domains.txt | xargs -I {} sh -c 'whois {} 2>&1 | grep -iq "no match\\|connection refused" && echo {}'

Step 5: Register the Domain
You can use Gandi.net to purchase the domain.
Step 6: Host a Server and Capture Traffic
Once you own the domain:
- Set up a web server (e.g., Nginx, Express.js)
- Watch for inbound traffic
- Inject controlled scripts or redirects if appropriate
Real-World Impacts
- Credential Theft: Fake login via OAuth or SSO
- Session Hijacking: If cookies or tokens are sent
- Malicious JS Injection: Via trusted
<script>references - Phishing: Redirection to fake login pages
- Analytics/Data Leaks: Users unknowingly sending data
💡 Tired of doing this manually?
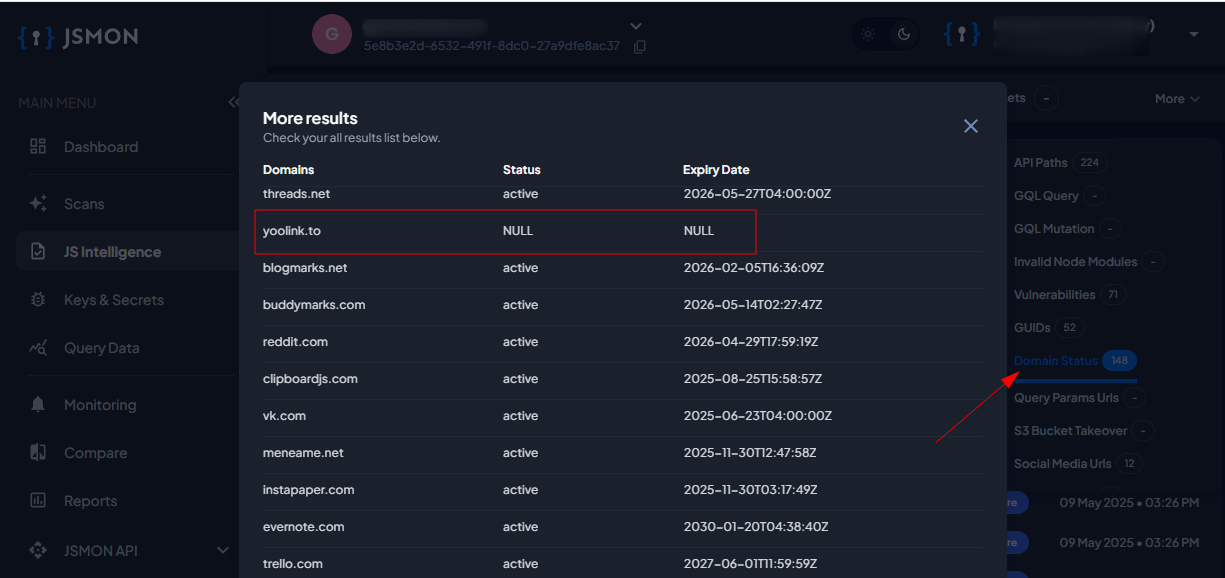
You can automate the entire workflow—from JavaScript extraction to second-order domain takeover detection—using jsmon.sh.
Let your recon run on autopilot while you focus on exploitation.
👉 Try jsmon.sh now and catch what others miss.
How We Can Help?
In 2026, Security tooling must deliver context—not just alerts. Jsmon continuously maps and monitors your JavaScript and web attack surface, identifying real risks like exposed endpoints, leaked secrets, misconfigurations, and client-side vulnerabilities as they emerge.
By combining context-aware analysis with continuous monitoring, Jsmon dramatically reduces false positives and helps teams focus on issues that are actually exploitable.
Secure your attack surface in real time with Jsmon.
Happy Hacking !