Finding Race Conditions: A Source Code Analysis Guide

For a long time, finding race conditions in web applications felt like gambling with timing. Security testers would throw bursts of concurrent requests at an endpoint, hope the server “tripped,” and then try to reproduce a bug that only appeared when network latency happened to line up just right.
That approach has become less effective. Modern production stacks are increasingly resistant to noisy, blind concurrency testing. Web Application Firewalls, strict rate limiting, auto-scaling infrastructure, and unpredictable jitter often mean you hit defenses faster than you hit a vulnerability.
To consistently uncover meaningful race conditions, you need to stop treating concurrency bugs as random accidents and start treating them as design flaws that can be mapped. The most reliable path is white-box analysis: studying source code to understand execution flow, state transitions, shared resources, and the precise moment where two operations can overlap in an unsafe way.
This article breaks down race conditions as they appear across two major worlds:
- Classic data races caused by shared memory contention in multithreaded applications.
- Logical TOCTOU (“time-of-check to time-of-use”) races common in asynchronous and event-driven stacks, where yielding execution creates exploitable windows.
Along the way, we’ll cover what to search for in real codebases, how modern race conditions show up in production systems, and the remediation techniques that actually close the window.
Understanding Race Conditions: Data Races vs. TOCTOU
At their core, race conditions are failures of ordering. A program expects events to happen in a specific sequence, but under concurrency, the ordering becomes unpredictable. When that happens, the program’s implicit “state machine” can transition into an invalid state.
From a source code perspective, there are two broad categories worth separating early, because they require different instincts during review:
- Memory-level data races: multiple execution threads read and write the same memory without correct synchronization.
- Logical races (TOCTOU): application logic checks a condition, yields, then acts later, assuming the condition is still true.
Modeling Web Vulnerabilities as State Machines
Most security-critical web functionality is a state machine even if nobody calls it that:
- A coupon is unused → validated → redeemed → marked used.
- An email address is old → change requested → confirmation token issued → change confirmed.
- A login attempt is normal → failed attempts increment → account locked.
A race condition happens when two concurrent “paths” in that machine overlap in a way the developer did not design for, and the system ends up in a state that should not exist.
Data Races and Memory Contention in Multithreaded Systems
In traditional multithreaded environments (common in Java and C#/.NET enterprise applications), race conditions often involve shared memory.
The Mechanics of Data Race Vulnerabilities
Imagine two threads operating on the same variable at roughly the same time. If there is no lock, atomic operation, or synchronization primitive controlling access, both threads can read the same initial value and overwrite each other’s updates.
A simple banking-style example shows how dangerous this is:
- Balance
X = 5 - Two concurrent operations each intend to add 10
The execution might look like this:
- Thread 1 reads
X = 5 - Thread 2 reads
X = 5 - Thread 1 computes
5 + 10 = 15 - Thread 2 computes
5 + 10 = 15 - Thread 1 writes
X = 15 - Thread 2 writes
X = 15
Correct final balance should be 25. Instead it becomes 15, because the second write effectively erases the first update.
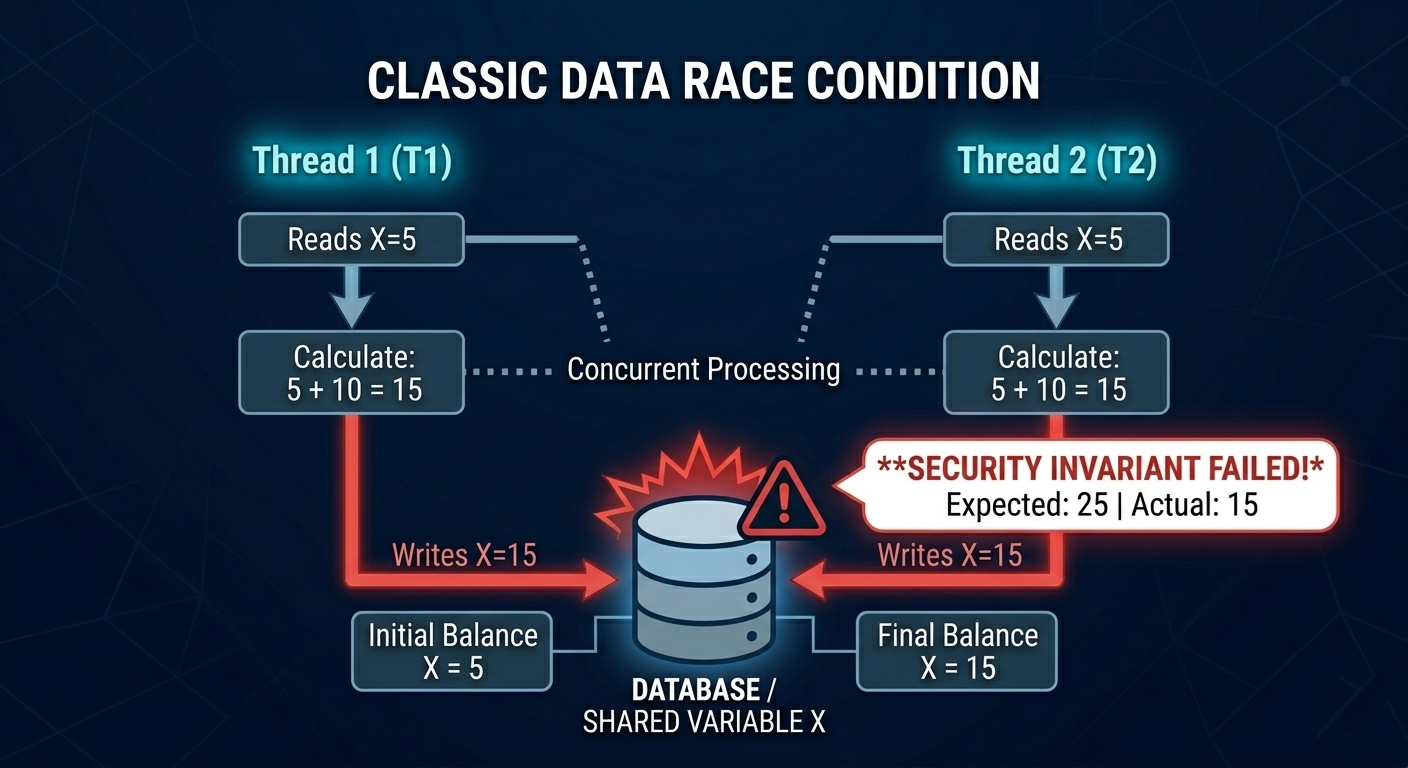
This is not just a “math bug.” In security-sensitive systems, inconsistent state like this can break invariants that authorization, anti-fraud logic, and auditing depend on.
Common Data Races in Enterprise Web Applications
In many web apps, per-request objects are isolated and safe. The biggest risks appear when data becomes shared across requests, such as:
- Global singletons
- Static variables
- Shared caches
- Cross-request in-memory maps
- Shared mutable configuration structures
Once two concurrent requests can touch the same memory, the application is in “race territory.”
TOCTOU Vulnerabilities in Asynchronous Web Applications
Modern stacks like Node.js and Go are designed around non-blocking I/O and concurrency-friendly primitives:
- Node.js uses an event loop and async callbacks/promises (
await). - Go uses goroutines and channels.
These systems can still be vulnerable to races, but the nature of the bug changes. Instead of shared-memory corruption, the most common problem is time-of-check to time-of-use (TOCTOU).
Time-of-Check to Time-of-Use (TOCTOU) Examples in Practice
A TOCTOU flaw often looks like this:
- Check whether something is allowed.
- Yield or wait for an async operation.
- Perform the action.
If multiple requests run concurrently, they can all pass the check while the system is “paused,” before any request reaches the point where state is updated.
A vulnerable Node.js pattern (coupon redemption)
Consider the following example:
// VULNERABLE NODE.JS PATTERN
async function applyCoupon(userId, couponCode) {
// 1. Time of Check
const coupon = await db.coupons.findOne({ code: couponCode });
if (coupon.used) throw new Error("Already used");
// 2. The Async Yield (Desync Window)
await performComplexFraudCheck(userId);
// 3. Time of Use
await db.coupons.updateOne({ code: couponCode }, { $set: { used: true } });
await db.users.updateOne({ id: userId }, { $inc: { balance: coupon.value } });
}
What makes this dangerous is the yield window:
- The code checks
coupon.used. - Then it pauses at
await performComplexFraudCheck(userId). - During that pause, 10 simultaneous requests can all pass the
coupon.usedcheck. - They all proceed to redeem before the first update reliably blocks the rest.
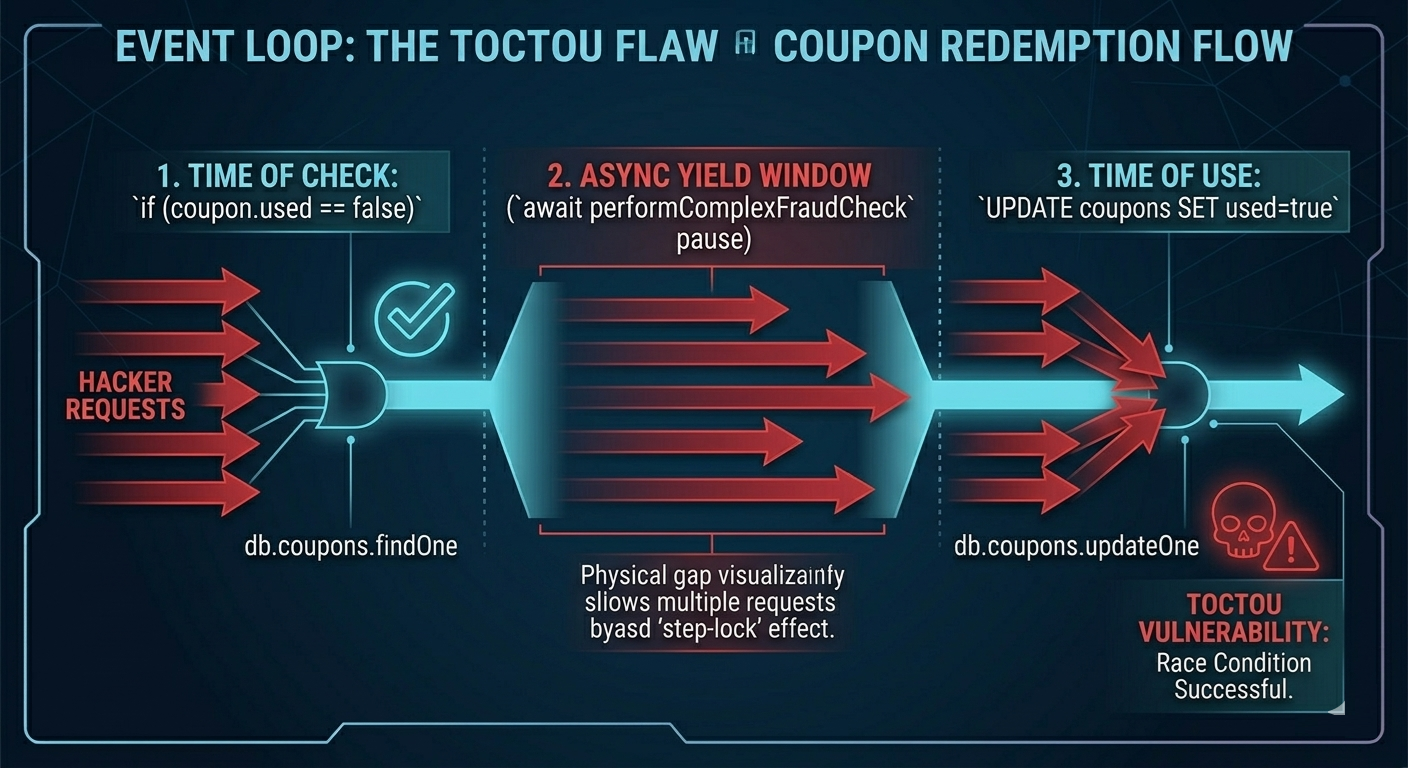
This can become:
- A financial loss issue (multi-use coupon redemption).
- A privilege escalation issue (reusing tokens or bypassing throttles).
- A workflow integrity issue (multiple state transitions that should be unique).
The important insight is that asynchronous yielding creates concurrency even in “single-threaded” environments, because multiple in-flight requests interleave between awaited operations.
Source Code Analysis: Identifying Race Conditions
Once you accept that race conditions are predictable based on structure, reviewing code becomes much more systematic. You are looking for:
- Shared state
- Non-atomic operations
- State transitions separated by waits
- “Check then act” logic
- Background workers that mix passed parameters with database lookups
Auditing Java and C#/.NET for Concurrency Bugs
Multithreaded apps often contain both safe and unsafe zones. The risk tends to concentrate in places where developers accidentally build shared state.
Static variable abuse
Static variables are one of the most common sources of cross-request contamination. If a static member stores request-specific information, then concurrent requests can overwrite it.
During review, identify:
- Static fields storing user-related data
- Static maps keyed by something weak (like session ID without strict controls)
- Singleton services holding mutable per-request state
Unsafe lock handling and deadlocks
Locks are easy to misuse. A classic failure mode:
- A lock is acquired.
- Code throws before the lock is released.
- The lock never releases, causing request pile-ups or denial-of-service.
Look for patterns where locks are not released in guaranteed paths, especially in code that can throw exceptions. In many languages, correct lock handling requires a structure equivalent to “always release,” such as releasing inside a finally block.
Useful C# signatures to search for
Search for:
ThreadSystem.ThreadingThreadPool
Then review the surrounding logic carefully, looking for shared variables updated without atomic operations like System.Threading.Interlocked, and without proper locking.
Useful Java signatures to search for
Search for:
java.lang.Threadstart()synchronizedwait()notify()notifyAll()
Pay special attention to static methods that mutate static state. If multiple requests can reach the same static mutator, you want to see explicit synchronization.
Auditing asynchronous code (Node.js and Go)
In async stacks, the strongest signal is state modification split by a yield point.
What counts as a yield point?
- In JavaScript:
await, promise chains, callback-driven I/O. - In Go: channel operations that can block, goroutine scheduling points, waits on shared resources.
Your goal is to find critical sequences like:
- Validate token →
await→ mark token used - Check quota → wait on external API → decrement quota
- Confirm not locked →
await→ increment failed-attempt counter
These are often subtle because the code reads “top to bottom” correctly, but concurrency changes the meaning.
Real-World Case Study: GitLab Race Condition Exploit
Some of the most instructive race conditions happen when different parts of the system disagree about what the “truth” is.
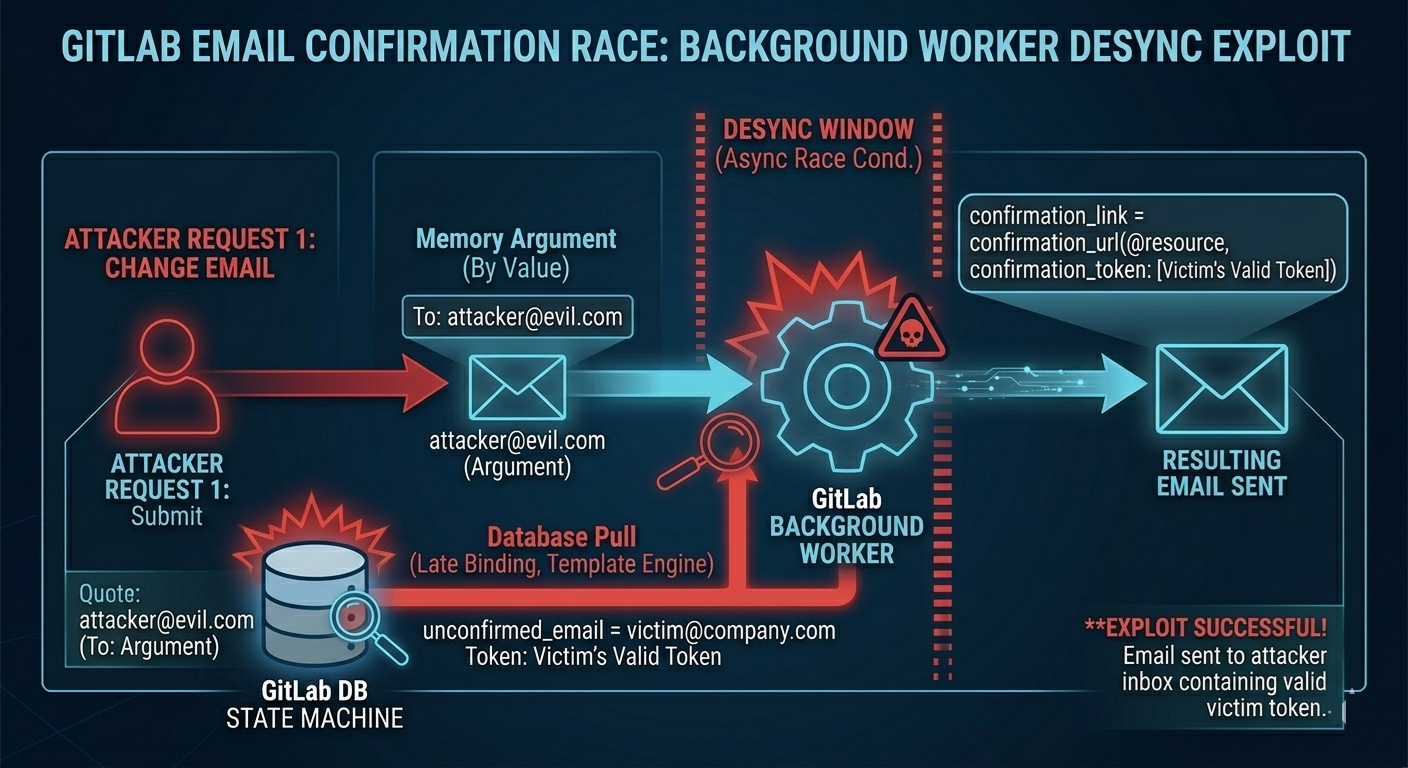
A widely discussed example involves GitLab’s integration with Devise (Ruby on Rails authentication). The issue is a desynchronization between:
- Values passed into a background job by argument.
- Values fetched later from the database by template rendering logic.
Architectural Flaws in Asynchronous Background Workflows
When a user changes an email address, the system:
- Stores the new email and a confirmation token in the database.
- Queues an email to a background worker.
A simplified snippet illustrates the risky behavior:
self.unconfirmed_email = self.email // from 'email' parameter...
self.confirmation_token = @raw_confirmation_token = Devise.friendly_token
// An email is queued to the background worker.
// Notice how the 'to' address is passed explicitly as an argument.
send_devise_notification(:confirmation_instructions, @raw_confirmation_token, { to: unconfirmed_email } )
The key problem is that the worker later generates the email body using a template engine that fetches current database state at render time.
Step-by-Step: Exploiting Background Worker Desyncs
- Attacker requests email change to
attacker@evil.com. - Worker queues email to
attacker@evil.comusing the “to” argument. - Before the worker renders the body, attacker triggers a second request to resend the token, but for
victim@company.com. - Database now contains victim email and a new valid token.
- Original worker runs:
- Sends to attacker-controlled address (argument).
- Renders body using current database token (victim’s token).
Outcome: the attacker receives a message sent to their inbox containing a token that applies to the victim’s email state.
Key Takeaways for Security Defenders and Code Reviewers
A black-box tester might see “token weirdness” and struggle to isolate it.
A source code reviewer sees the exact boundary:
- One part of the workflow trusts in-memory arguments.
- Another part trusts database state at a later time.
- The asynchronous handoff creates a window where those can be made inconsistent.
This is precisely why reviewing state machines beats blind traffic: it reveals where the system can desync.
High-Impact Targets for Race Condition Exploits
Once you locate a race window, the next question is whether it leads to a meaningful outcome. Some classes of races consistently produce high-impact security issues because they sit on business logic boundaries.
TOCTOU file upload windows
A common pattern:
- Upload saved temporarily (for example,
/uploads/temp.php). - Validation runs (extension checks, antivirus scanning).
- File is deleted or moved.
If the file is executable or reachable during the validation window, an attacker can sometimes execute it before the system removes it.
Limit overruns and state bypasses
Endpoints enforcing “one-time” or “limited” behavior are frequent victims:
- Promo codes that should be single-use
- Cart discounts intended to apply once
- Inventory reservations
- Gift card redemption
- Trial activations
Racing requests can sometimes apply the “benefit” multiple times before the system commits the “used” state.
OAuth, OTP, and rate-limit bypass patterns
Authentication flows are state machines by nature:
- Send OTP → verify OTP → increment failures → lock out
If checks and counters are separated by yields or non-atomic updates, attackers can sometimes bypass:
- Attempt counters
- Account lock logic
- Step-up verification constraints
Precision exploitation over the internet
Hitting a narrow race window across real network conditions is difficult. Modern techniques aim to remove jitter and force near-simultaneous processing. One notable method is the HTTP/2 single-packet approach, where multiple requests are held back until the last byte and then released together to synchronize server-side processing.
The underlying idea is simple: if the infrastructure defeats “spray and pray,” the attacker tries to control alignment rather than volume.
Remediation Strategies: Database Locking and Synchronization
One of the most common misconceptions is that “put it in a database transaction” automatically prevents races.
Why transactions alone often do not solve it
Many databases default to a Read Committed isolation level. Under that model:
- Two concurrent transactions can still read the same initial state.
- Both can pass a check based on that read.
- Both can attempt writes, and depending on the update pattern, the outcome may still violate your intended invariants.
The fix is not just “transaction,” but transaction + correct locking strategy.
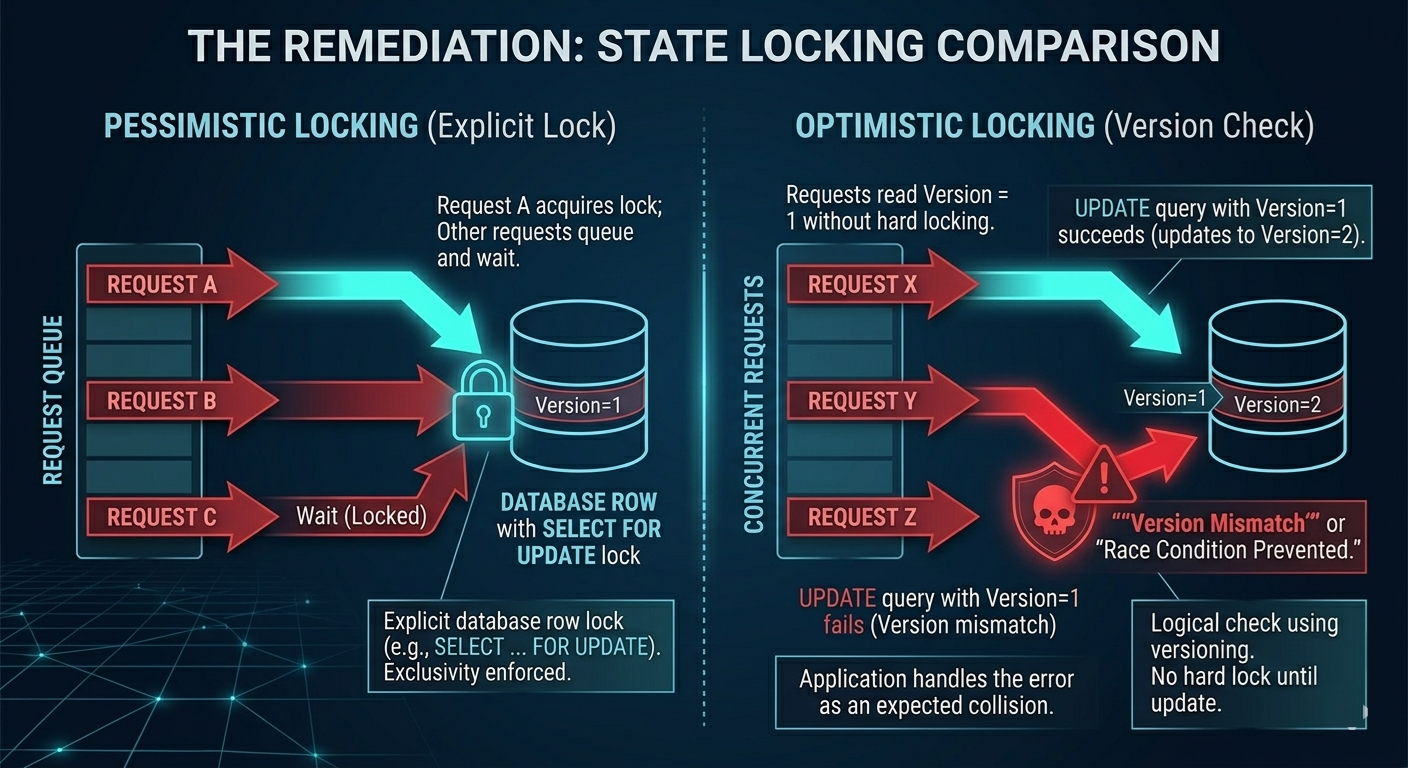
Pessimistic database locking
If your logic depends on exclusivity, lock the row before proceeding.
A common approach is selecting rows with an explicit lock such as FOR UPDATE, forcing other concurrent transactions to wait for the first to complete. This is a strong defense for “single-use” resources (tokens, coupons, inventory reservations), because it serializes access at the database level.
Optimistic locking via versioning
Optimistic locking assumes collisions are possible and detects them safely.
A typical pattern:
- Add a
versioncolumn. - On update, require the expected version to match.
- If another request already updated the row, the current update fails cleanly.
Conceptually:
- “Update only if nobody else changed this since I last read it.”
This is often a good fit when you want performance and expect collisions to be rare, but must handle them correctly.
Atomic operations and synchronization in C# and Java
For true shared-memory data races, fix means:
- Atomic operations for simple increments and counters (for example, methods like
Interlocked.Add()in C#). - Explicit synchronization blocks for complex operations on shared state.
- Strict lock release discipline (ensuring locks are released even when exceptions happen).
The goal is to enforce a rule that the system cannot violate:
- Only one thread can manipulate the shared resource at a time.
- The critical section is as small and explicit as possible.
Automating API Reconnaissance for Race Conditions
In real bug bounty and pentest work, you rarely get backend source code. Instead, you often start from the frontend and infer backend workflows. Tools like jsmon help by extracting clues from JavaScript and source maps, pointing you to where asynchronous state machines likely exist.
Exposing asynchronous endpoints
Frontend code and source maps can reveal:
- Undocumented API routes
- Internal service paths
- Keywords like
async,background,worker,job,queue
These hints can surface endpoints such as /api/v2/payment/process_async or /user/email/confirm_background, which are strong indicators of async workflows worth closer review.
Mapping the check-and-use chain
Many TOCTOU races span multiple endpoints. If the frontend calls /cart/validate and then /cart/checkout, you may have identified the “check” and the “use” steps, which lets you focus concurrency testing on the exact sequence instead of fuzzing blindly.
Conclusion: The Future of Race Condition Testing
The era of “throw 100 threads at the endpoint and hope” is fading. Not because race conditions are disappearing, but because infrastructure is increasingly built to suppress noisy, uncoordinated traffic.
Race conditions remain one of the most severe classes of vulnerabilities because they break assumptions at the heart of security controls: uniqueness, ordering, and state integrity.
To find them reliably today, the most effective mindset is architectural:
- Treat workflows as state machines.
- Identify where checks and updates are separated.
- Look for yield points and asynchronous handoffs.
- Track what is stored in memory versus what is fetched from shared state later.
- Validate whether database isolation and locks truly enforce exclusivity.
References and Further Reading
- PortSwigger Research: Smashing the State Machine (James Kettle)
- CWE-362: https://cwe.mitre.org/data/definitions/362.html
- CWE-368: https://cwe.mitre.org/data/definitions/368.html
- OWASP Secure Code Review Guide
- Dynamic Data Race Detection in Go Code (Uber Engineering)
- Race Conditions Can Exist in Go (Checkmarx)
- OWASP Node.js Security Cheat Sheet